Inscription / Connexion Nouveau Sujet
algorithme
Bonjour
Créez un algorithme qui génère aléatoirement une suite de nombres entiers et qui s'arrête lorsque qu'un nombre généré est multiple d'un entier faisant déjà parti de la liste.
On pourra si on le souhaite aussi traiter cet énoncé sous l'angle des probabilités en définissant une variable aléatoire X égale au rang ou le processus s'arrête , on pourra ensuite donner la loi de P(X=k).
salut
j'avais vu ce sujet avant de commencer une visio avec mes élèves ... et quelques remarques avant de commencer la prochaine ...
j'avais eu la même idée que LittleFox mais pas pensé à la structure set que je ne connais pas trop mais à faire une liste ...
cependant j'ai une question : tu utilises la "méthode" (c'est comme ça que l'on dit je crois bien) add mais peut-on avec set utiliser la "méthode" append comme pour les listes ?
en fait c'est vraiment bien cette structure set et la fonction any
il y a aussi ce
if __name__ == "__main__":
solution()[/code
sinon je ne comprends pas aussi un autre truc
def alea():
return 4 # Ce nombre a été généré aléatoirement
merci par avance

Bonjour,
La fonction =ent(aléa()*100) sur Excel te donnera au moins de bonnes valeurs à toi
d'y rajouter un frein genres =mode()
Bonjour, pour carpediem :
La fonction alea() renvoie toujours 4 ici. Je pense que c'est pour essayer le code ou pour la petite blague vu que le 4 a certainement été choisi aléatoirement par le concepteur 😁
Concernant la fin du code, cela permet de lancer un script python avec des paramètres en ligne de commande et surtout cela permet d'avoir un script qui fonctionne lorsqu'on l'exécute mais lorsqu'il est importé n'exécute pas (ici) solution (). But: importer juste les def sans l'execution de celles ci. Je ne sais pas si je suis clair.
@carpediem
Le return 4 est une blague
C'est un nombre aléatoire entre 0 et 100, ... qui est toujours 4 
Le nom alea est effectivement inspiré d'Excel, bien vu dpi mais je ne crois pas que tu puisse mettre le e aigu.
La fonction randint(0,100) du module python random te donnera un nombre PSEUDOaléatoire entre 0 et 100.
On peut le faire avec une list mais ce sera moins efficace qu'avec un set. En effet si y=E(X), le nombre moyen de nombre avant une répétition, l'algorithme avec la liste va être en O(y²) alors qu'avec un set il va être en O(y). Pour ma fonction alea, comme y=1, il n'y a pas de différence 
Il n'y a pas de append pour un set, ça n'aurait pas de sens d'ajouter un élément à la fin d'un set. C'est quoi la fin d'un set 
Je te renvoie ici![]() et ici
et ici ![]()
En résumé, pour les listes il est efficace de :
append(x) : ajouter un élément à la fin de la liste
pop() : enlever et retourner l'élément à la fin de la liste
[ i] : accéder à l'élément à l'index i (note: [-1] est l'élément à la fin de la liste, [-2] celui avant, etc)
Alors que pour les set il est efficace de:
add(x) : ajouter un élément à l'ensemble
remove(x) : retirer un élément à l'ensemble (erreur si l'élément n'est pas dans l'ensemble)
discard(x) : retirer un élément à l'ensemble, s'il y est.
x in set : vérifier si x est dans le set
Je t'invite à regarder aussi la structure dict, une des structures les plus utiles en python.
Et pour le
if __name__ == "__main__":
main()C'est juste pour éviter que main() ne soit appelé si un autre script fait un import de notre script. Dans le cas d'un script tout seul, ça ne change rien, main() est appelé.
Petite remarque: pour l'algo proposé par LittleFox il faudrait traiter le cas où un des nombres (choisi ou déjà choisi) est 0 On peut aussi simplement prendre des nombres entre 1 et 100.
LittleFox
Je ne comprends pas pourquoi l'utilisation d'un set rend l'exécution linéaire...
Certes, set est optimisé pour détecter si un élément est déjà présent dedans, mais ici, on vérifie une propriété plus compliquée, qui nous oblige à itérer sur le tout le set (dans le any...). On obtient donc la même complexité qu'avec une liste...
Je pense néanmoins qu'il y a moyen d'améliorer la complexité asymptotique, je vais regarder ça
En prenant des nombres entre 1 et 100 avec X le rang du nombre etant un multiple: p(X=1)=0 evident. p(X>100)=0 evident.
pour le reste:
 Cliquez pour afficher
Cliquez pour afficher@weierstrass
Ah, bien vu. L'algo aurait été linéaire O(y) si on vérifiait juste que le nombre n'avait pas été déjà produit. Mais comme on doit vérifier qu'aucun diviseur n'a déjà été produit c'est plus compliqué. Dans la version que je donne c'est même moins efficace qu'avec une liste.
Je pense qu'il y a moyen d'améliorer en O(y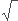 z) avec z la valeur maximale de x (100 dans ce cas). En testant si les diviseurs sont dans l'ensemble.
z) avec z la valeur maximale de x (100 dans ce cas). En testant si les diviseurs sont dans l'ensemble.
@jarod128
Effectivement diviser par 0 risque de poser problème
Bien joué pour les probas. Comment les as-tu calculées? Chaque nombre ayant un nombre différent de diviseurs/multiples, tu as testé toutes séries de nombre aléatoires possible?
Dans la version que je donne c'est même moins efficace qu'avec une liste.
je ne vois pas pourquoi car ta boucle while s'arrête dès qu'on a trouvé que c'est un multiple ... avec une liste on ferait de même il me semble ...
LittleFox loi des grands nombres, avec 1010 essais. 
Par contre, X=6 semble être la valeur ayant la plus grande probabilité. Il y a peut être même une loi normale centrée en 6. Qu'en pensez vous?
@carpediem
Tu as raison on ferait de même avec une liste.
Mais au lieu de juste stocker la variable à la fin d'une liste, je dois faire plusieurs opérations pour calculer l'entrée dans le set (cachées dans add) typiquement un hash et un modulo. On parle de 25% plus lent. Ça reste O(y²).
@jarod128
Wow 1010, c'est beaucoup
Je pencherais plus vers une loi de poisson que normale. La loi normale acceptant des valeurs négatives.

