Inscription / Connexion Nouveau Sujet
test sur la moyenne
Bonjour,
On dispose d'un traitement satisfaisant dans 70% des cas. Un labo propose un nouveau traitement et affirme qu'il est meilleur; sur 200 malades avec ce nouveaux traitement, on observe 148 guérisons.
Décider au seuil de si le traitement est plus efficace.
Je passe les détails sur l'estimateur de la variance , on a qui converge en loi vers
on a et
je pose :
: l'ancien traitement est meilleur que le nouveau
: Le nouveau est meilleur que l'ancien
la lecture de ma table donne , je trouve
Ainsi la région d'acceptation de nouveau traitement est :
J'ai voulu aller plus loin, et tester l'erreur de seconde espèce, i.e la probabilité que le nouveau traitement est meilleur sachant le l'ancien est meilleur.
On a donc
donc
Ce qui nous donne un intervalle d'acceptation de l'ancien traitement :
Ma question est la suivante, le premier test permet de valider le nouveau traitement car est dans l'intervalle de 1ère espèce.
Le second test rejette le nouveau traitement, car il dit que si est dans
il y a un truc qui m'échappe...
Je recommence
On acceptera si
la lecture de ma table donne , je trouve
On retombe sur le même résultat :
On acceptera si
donc l'intervalle est donc la région d'acceptation l'ancien traitement est :
En conclusion, le risque de première espèce ne permet pas de valider le nouveau traitement, mais simplement de donner une région d'acceptation.
En revanche le risque de second espèce rejette le nouveau traitement !
Vous en pensez quoi?
Mais le
Bonsoir,
je crois que tes hypothèses sont mal choisies.
Presque par définition l'hypothèse nulle H0 doit-être le nouveau traitement est comme l'ancien.
Et c'est cette hypothèse qui permet de faire le calcul avec
J'ajouterais que ton premier calcul montre que l'ancien traitement n'est pas plus mauvais que le nouveau et que ton second calcul montre que le nouveau n'est pas meilleur que l'ancien.
Ceci étant dit au seuil de risque 1% et d'après les données fournies.
Merci Verdurin,
Le test porte bien sur les données du nouveau traitement i.i.d. de loi de Bernoulli, je ne vois pas pourquoi on utilise
d'un échantillon qui n'existe pas (correspondant à l'ancien traitement ), il me semble que l'on doit prendre
Pour les hypothèses, oui j'aurais dû prendre
Ce que je viens de comprendre de ton intervention est le suivant :
On a un risque si
cependant si
Dans les deux cas, on ne peut pas rejeter ou
donc on garde l'ancien traitement.
Si
si
si
Et puisque , on a
,
est rejeté, donc on choisit le nouveau traitement
Pour faire le test on part de l'ancien traitement qui est bien connu, on a pas besoin de faire une étude sur lui et on sait qu'il est satisfaisant dans 71% des cas.
On cherche à savoir à partir d'un échantillon si le nouveau traitement est meilleur.
Soit la probabilité que le nouveau traitement soit satisfaisant pour un cas pris au hasard.
On fait un essai sur 200 cas et on trouve une estimation de égale à 0,74.
On peut donc espérer que le nouveau traitement soit meilleur.
Mais il se peut aussi qu'il ne s'agisse que d'une fluctuation due au hasard.
L'objet du test est de savoir si une telle fluctuation est vraisemblable ou non.
La valeur de 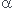 ( ici 0,01 ) indique que l'on ne croira qu'il y a une vraie amélioration que si la probabilité d'avoir un tel résultat par hasard est inférieur à .
( ici 0,01 ) indique que l'on ne croira qu'il y a une vraie amélioration que si la probabilité d'avoir un tel résultat par hasard est inférieur à .
Il est important de savoir que l'on peut faire les calculs avant de faire la mesure.
On a
Pour un échantillon de taille on va rejeter
si la valeur observée est plus grande que
Il est complètement déraisonnable de faire un test à partir des valeurs trouvées dans l'échantillon.
Lapsus calami
Pour faire le test on part de l'ancien traitement qui est bien connu, on a pas besoin de faire une étude sur lui et on sait qu'il est satisfaisant dans 71% 70% des cas.
je ne comprends pas, pour utiliser la loi normale, il faut que converge en loi vers
ce que j'ai montré.
Si on utilise la variance de l'ancien traitement,efficace à 70%, nous donne une variance comme tu le dis
or ne converge pas vers
puisque tu utilises la variance de l'ancien traitement.
Il y a un truc qui m'échappe
Sous l'hypothèse nulle il est clair que
converge bien en loi vers
.
C'est ce résultat que l'on utilise car l'ancien traitement est bien connu et on sait que pour lui .
Une remarque encore :
pour utiliser la loi normale, il faut que
Ce que tu n'as pas montré est que
C'est pourtant ce que tu utilises.
je ne suis pas trop d'accord, ou alors je me suis mal exprimé :
je reprends depuis le début et cette fois je pose les hypothèses suivantes :
et je sais que converge en loi vers
avec
le paramètre inconnue.
On acceptera si
or est vraie donc
donc
donc
donc on a
et ça c'est juste mathématiquement, en utilisant les estimateurs.
Possible que la majoration ne soit pas optimale ...
Une remarque encore :
pour utiliser la loi normale, il faut que
Ce que tu n'as pas montré est que
C'est pourtant ce que tu utilises.
je pose des questions sur les points qui me bloquent, veux-tu la démonstration entière (j'utilise le lemme de Slutsky et le TCL)
je reprends depuis le début et cette fois je pose les hypothèses suivantes :
Quelque part dans ton cours on doit lire que l'hypothèse nulle permet de faire les calculs, en d'autres termes c'est nécessairement une égalité.
En effet elle ne permet aucun calcul de probabilité.
Quand tu dis
ah non, j'ai jamais dis ça :
Mais c'est ce que tu utilisas pour faire tes calculs. Qui sont donc vides de sens.
merci Verdurin, mais je n'ai rien de tout ça dans mon cours...les exams sont dans moins de deux semaines, je vais mettre de côté cet exo
Je me demande ce que tu as dans ton cours.
Je te conseille de retenir un point fondamental sur les tests statistiques :
l'hypothèse nulle doit permettre de faire un calcul de probabilité avant que l'on fasse les mesures.

je crois avoir compris
Donc on a
donc
puisque et que la région d'acceptation du test avec un niveau de confiance de
est
, on garde l'ancien traitement.
C'est encore un peu flou...
merci verdurin c'est la réponse que tu as donnée le 10-05-21 à 18:14, mais je pense que c'est compris.
Je pensais que c'était quand même plus simple que ça les tests d'hypothèses ...
Une autre façon de rediger (niveau bts)
On dispose d'un traitement satisfaisant dans 70% (c'est p0) des cas. Un labo propose un nouveau traitement et affirme qu'il est meilleur; sur 200 (c'est n) malades avec ce nouveau traitement, on observe 148 (c'est x) guérisons.
Nous allons realiser un test unilateral de conformite d'une proportion.
Les conditions n>30, x>=5 et n-x>=5 sont remplies.
Conclusion:
Au risque 1% on admet donc que le nouveau traitement n'est pas plus efficace que l'ancien.
merci alb12, c'est du niveau BTS? Car un prof certifié est censé pouvoir enseigner dans ces classes, non?
oui en bts on applique des "recettes" sans demo (pour toi c'est insuffisant).
j'ai choisi cette presentation en bts car on peut facilement les programmer.
Mais d'autres enseignants utiliseront les notions de regions de rejet ou d'acceptation.
D'autres encore prefereront la notion de probabilite critique.
Les etudiants de bts qui feront du controle qualite ont besoin des tests d'hypothese.
Un prof certifie peut en effet avoir à enseigner en bts.
J'aimerai savoir si cette approche est correcte :
Je cherche l'intervalle de confiance de la moyenne
On admet que car
est très grand
avec
donne
On conclut que la moyenne est dans
avec un niveau de confiance de 99%
avec les hypothèses
est envisageable puisque
donc on accepte
je crois que tu commets une erreur
puisque H0:p=0.7 (p inconnue, proportion dans la population dont est issu l'echantillon) on fait les calculs sous cette hypothese
c'est donc (Xn-p)/(sqrt(p*q/n))=(Xn-0.7)/(sqrt(0.7*0.3/n) qui suit asymptotiquement une loi normale centree reduite notee U
ton sigma_n n'est pas coherent avec le p du numerateur
ensuite on cherche un demi intervalle (car H1:p>0.7, test unilateral) de fluctuation de la proportion dans la population
c'est [p;p+t*sqrt(p*q/n)]=[0.7;0.7+t*sqrt(0.7*0.3/n)]=[0.7;0.775] (region d'acceptation) avec P(U>t)=alpha=0.01 (pas de valeur absolue autour de U pour un test unilateral)
la region de rejet est donc ]t*sqrt(p*q/n);inf[=]0.775;inf[
ici x/n=148/200=0.74 (proportion dans l'echantillon) n'est pas dans la region de rejet
donc on ne rejette pas H0
le risque de premiere espece (rejeter H0 alors qu'elle est vraie) est alpha
le risque de deuxieme espece (accepter H0 alors qu'elle est fausse ) n'est en general pas connu (sauf si on connaît la distribution sous H1)
c'est pourquoi un test n'a d'interet que si on rejette H0 car le risque d'erreur est alors connu (alpha)
J'ai posté ailleurs désolé alb12
lorsque tu dis :
ton
Je crois que si car il ne dépend pas de
Sinon, as-tu un ouvrage à me conseiller ?
C'est dingue j'ai un livre qui me dit le contraire de ce qui est noté dans mon cours.
Dans mon cours
Pour accepter il faut que
appartienne la région d'acceptation du test au niveau de confiance
et le risque de première espèce est au plus égal à
Dans mon livre :
[...]On pourra rejeter avec un risque de se tromper maîtrisé (par
[...]) mais on NE POURRA JAMAIS VALIDER
avec un risque de se tromper prédéfini. [...]
Ce que j'ai mis en rouge est une coquille, non?
« On accepte H0 » n'est pas synonyme de « on valide H0 ».
Dans ton exemple on ne peut pas rejeter H0, donc on l'accepte.
Mais il est possible qu'un échantillon plus grand permette de voir que le nouveau traitement est un peu meilleur que l'ancien.
On ne valide pas le fait que les deux traitements ont la même proportion de réussite.
Simplement on a pas vu de différence statistiquement significative sur cet échantillon.
salut
j'ai suivi depuis un bout de temps et n'étais pas intervenu puisque d'autres étaient présents cependant ... je "dois" réagir ...
tout d'abord pour mousse42 :
quand on débute les tests on se fout dans un premier temps des risques de première ou deuxième espèce ... tu as les temps de voir cela plus tard ...
on peut en parler comme ça pour éclaircir un peu la situation pour comprendre la philosophie d'un test ... dont l'idée est de savoir si la situation a significativement changé : l'idée est de pouvoir rejeter H_0 pour pouvoir accepter H_1 (et non pas d'accepter H_1 pour rejeter H_0 : ça revient au même mais la nuance est d'importance)
dans toute la suite j'utilise les notations suivantes :
on a une population de taille N (en général très grande) dont on étudie un caractère :
quantitatif X de moyenne M et d'écart type S
qualitatif ou du type binomial de proportion p (du genre yeux bleu/pas bleu, vrai/faux, bon/pas bon) et d'écart type
on extrait ensuite de cette population un échantillon de n et on en calcule la moyenne m et l'écart type s ou la fréquence f
la théorie de l'échantillonnage et ses fluctuations dit que :
la variable aléatoire Y qui associe à un échantillon sa moyenne suit approximativement la loi normale de moyenne m et d'écart type
la variable aléatoire F qui associe à un échantillon la fréquence (de vrai, de "bon", de "succès") suit approximativement la loi normale de moyenne p et d'écart type
je ne rentre pas dans les détails (condition d'utilisation, ... bal bla bla, ...)
mais ensuite on peut donc faire tous les calculs que l'on veut et calculer les probabilités :
P(Y < t), P(Y, > t), P(m - h < Y < m + h) = 0,95 (intervalle de confiance de la moyenne au niveau de confiance 95%)
et idem avec F ...
en particulier par exemple l'intervalle de confiance de la moyenne au niveau de confiance 95% dit simplement que dans 95% des cas la moyenne de l'échantillon sera dans cet intervalle
tout cette théorie se base sur le fait qu'on connait les paramètres de la population totale
maintenant dans la réalité on ne connait pas toujours les paramètres de la population totale et pour les connaitre on va faire de l'estimation à partir des paramètres obtenus à partir d'un (ou plusieurs) échantillon(s) (voir un cours à ce sujet mais on a les même résultats mais en partant cette fois des valeurs de l'échantillon)
et enfin pour en arriver au tests : on a une norme : on veut découper des planches de longueur 200 cm, on veut remplir des canettes de volume 150 mL, on a p % de guérison comme dans ton cas et on veut vérifier s'il y a un changement ou si on ne peut pas accepter qu'il y ait un changement
ici un traitement donne p = 70% de guérison : c'est la norme qui est connu pour ce traitement et on veut savoir si un autre traitement donne autre chose (test bilatéral) ou mieux (test unilatéral)
l'hypothèse nulle est donc toujours H_0 p = 0,7
et dans le cas présent l'hypothèse alternative est H_1 : p > 0,7 (le traitement est mieux meilleur !! enfin on veut vérifier si on peut accepter cette affirmation)
et on va tester au niveau de confiance b = 99% ou au seuil de risque a = 1%
là où je ne suis pas d'accord avec alb12 (pour son intervalle) : dans un test bilatéral il y a deux régions de rejet et une seule dans un test unilatéral :
avec l'approximation par la loi normale (centrée réduite) on cherche donc le réel t tel que P(T < t) = 0,99
l'intervalle ]-oo, t] est la zone de non rejet de H_0
l'intervalle [t, +oo[ est la zone de rejt de H_0 (et donc d'acceptation de H_1)
ensuite on prélève un échantillon et on regarde :
avec n = 200, p = 0,7 on trouve que t = 2,33 puis que P(F < 0,775) = 0,99
que signifie l'intervalle ]-oo ; 0,775] ?
toujours d'après la théorie de l'échantillonnage si la proportion du traitement est 0,7 alors dans 99% des cas la fréquence de guérisons appartient à cet intervalle
ici avec l'autre traitement l'échantillon donne f = 0,74 : c'est donc une valeur "normale" au niveau de confiance 99% si la proportion réelle est aussi 70% de guérison
et donc on ne peut pas conclure que le nouveau traitement est meilleur et on ne peut pas rejetre l'hypothèse nulle ...
si par exemple on avait obtenu f = 0,78 (ou plus) avec le nouveau traitement alors on aurait pu conclure (selon la théorie de l'échantillonnage) que cette valeur n'est pas seulement due aux fluctuations d'échantillonnage mais "très certainement due au risque de 1%" au fait que la proportion de guérison avec le nouveau traitement est meilleure
et pour conclure sur les risques de première/deuxième espèce :
la cause essentielle ben c'est cette fluctuation d'échantillonnage encore et toujours :
soit le nouveau traitement n'est pas meilleur mais je tombe sur un échantillon (où ils guérissent tous) et me font conclure que le nouveau traitement est meilleur
soit le nouveau traitement est (réellement) meilleur mais je tombe sur un échantillon qui ne me permet pas de le conclure et donc que je ne peux pas refuser H_0
pour finir avec ma nuance plus haut : le pire cas est d'accepter H_1 qui est faux : cela peut en coûter la vie des patients : il vaut mieux accepter (peut-être à contrecur) que le nouveau traitement n'est pas meilleur même s'il l'est que le contraire ...

 je vais faire un break
je vais faire un breakcarpediem
"là où je ne suis pas d'accord avec alb12 (pour son intervalle) : dans un test bilatéral il y a deux régions de rejet et une seule dans un test unilatéral : "
ok mais des le debut je sais que x/n>0.7 c'est pourquoi je demarre l'intervalle à 0.7

 statistiques en post-bac
statistiques en post-bac