Inscription / Connexion Nouveau Sujet
algorithme de Dijkstra (Python)
Bonjour,
j'ai implémenté l'algorithme de Dijkstra avec une matrice d'adjacence et je fais face à quelques problèmes, pourriez-vous m'aider s'il vous plaît?
import numpy as np
Inf = np.inf
Matrice_Adj= np.array([ [0,148,85,Inf,Inf,Inf], [148,0,157,148,Inf,Inf], [85,157,0,302,87,Inf], [Inf,148,302,0,253,167], [Inf,Inf,87,253,0,428], [Inf,Inf,Inf,167,428,0] ])
def dijkstraDist(G, depart):
# On récupère le nombre de sommets du graphe
N = np.size(G,0)
# Initialisation du tableau des plus courts chemins
# Le booléen pour savoir si le sommet a déjà été sélectionné
pcc = list()
for i in range(N):
pcc.append([Inf, False])
sommet_u = depart
dist_u = 0
pcc[depart][0] = 0
# Le premier sommet sélectionné est le sommet depart
pcc[depart][1] = True
# On compte le nombre de sommets sélectionnés
compteur = 0
while compteur != N-1:
# À chaque étape, la solution optimale doit être conservée (pour sélection du sommet correspondant à l?étape suivante)
minimum = Inf
# Étape de relâchement
for k in range(N):
# Si le sommet k n?a pas encore été sélectionné
if pcc[k][1] == False:
dist_uv = G[sommet_u][k]
# Distance totale du chemin s -> ... -> u -> v
dist_totale = dist_u + dist_uv
# Mise à jour du tableau des plus courts chemins
if dist_totale < pcc[k][0]:
pcc[k][0] = dist_totale
# Mise à jour de la solution minimale à cette étape
if pcc[k][0] < minimum:
minimum = pcc[k][0]
sommet_suivant = k
# On a traité complétement un sommet
compteur = compteur + 1
# Le sommet à traiter est sélectionné et d[u] est mis à jour
sommet_u = sommet_suivant
pcc[sommet_u][1] = True
dist_u = pcc[sommet_u][0]
return(pcc)
def dijkstraPCC(G, depart, arrivee):
pcc = dijkstraDist(G, depart)
# Reconstitution du plus court chemin
chemin = list()
# On reconstitue le plus court chemin d?arrivee vers depart
ville = arrivee
chemin.append(ville)
while ville != depart:
ville = pcc[ville][2]
chemin.append(ville)
# On demande le miroir de la liste obtenue pour que les sommets apparaissent dans l?ordre
return(list(reversed(chemin)))Tout d'abord, j'ai créé la matrice d'adjacence correspondant à mon problème, en réalité chaque sommet représente une ville. Ai-je le droit de faire(avant de définir la fonction): 0=ville1, 1=ville2, 2=ville3....; 5=ville6 et d'ensuite mettre le nom de la ville dans l'appel à la fonction ?
Puis j'ai implémenté un algorithme qui, à partir d'un sommet donné, donne tous les plus courts chemins. J'aimerais faire apparaître les villes dans le return, mais je ne sais pas comment faire? Et est-il possible de faire en sorte qu'il n'y ait pas le True dans le renvoi?
ensuite , pour le deuxième code, j'aimerai également faire apparaitre les villes. De plus, quand je le teste voici le message d'erreur, je ne comprends pas où est mon erreur:
>>> dijkstraPCC(Matrice_Adj,1,5)
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/********/******
ville = pcc[ville][2]
IndexError: list index out of rangeJe vous remercie par avance, bonne soirée
Bonsoir.
Comment sait-on que le script tourne ?
Combien de temps lui faut-il pour mouliner ?
Un conseil : indentez les commentaires liés au code auquel ils se rapportent.
Pour répondre à votre première question, vous devez déclarer tout objet (variables, fonctions, ...) avant de l'utiliser.
Bonsoir ,
Le script tourne parce que je l'ai testé avec comme point de départ le sommet 2 et il me renvoie ce que j'avais calculé à la main
J'ai essayé de mettre 0= Lyon', 1=´Paris'....
Mais ça m'affiche un message d'erreur
Je suis désolée je ne peux pas vous mettre une capture d'ecran car je n'est pas accès à mon ordinateur ce soir
Bonjour.
1 / Message d'erreur.
Comme l'indique le message d'erreur :
>>> dijkstraPCC(Matrice_Adj,1,5)
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/********/******
ville = pcc[ville][2]
IndexError: list index out of range
Il s'agit d'un erreur d'indexation puisque vous essayez d'atteindre un élément de la liste de liste pcc inexistant. Le contenu étant défini dans la fonction dijkstraDist( ) :
pcc = list()
for i in range(N) :
pcc.append([Inf, False])
Pour la correction, voir ci-après.
2 / Ajout des villes .
Il suffit de remplacer le code existant :
pcc = list()
for i in range(N) :
pcc.append([Inf, False])
par :
# liste des villes
l_villes = ["Ville_0", "Ville_1", "Ville_2", "Ville_3", "Ville_4", "Ville_5"]
...
# generation de la liste de listes des plus courts chemins
pcc = [ [ville, Inf, False] for ville in l_villes]
idx_ville = 0
idx_dist = 1
idx_select = 2
...
Voir la compréhension de liste en Python.
Bonjour
Merci de votre réponse
Mais pour le message d'erreur , je ne comprends pas ce que je dois corriger
De plus , pour les villes , je ne connais pas la fonction que vous avez utilisé et je ne sais donc pas comment numéroter les 3 autres villes
Avec votre code, on obtient une liste de liste (3x2) comme celle-ci :
pcc : [[inf, False], [inf, False],
[inf, False], [inf, False],
[inf, False], [inf, False]]
Avec mon code, vous obtenez une liste de liste (3x3) :
pcc : [['Ville_0', inf, False], ['Ville_1', inf, False],
['Ville_2', inf, False], ['Ville_3', inf, False],
['Ville_4', inf, False], ['Ville_5', inf, False]]
Le nom de la ville est maintenant compris dans votre table pcc.
oui j'ai bien compris ça, mais je ne comprends pas:
idx_ville = 0
idx_dist = 1
idx_select = 2
Puis-je mettre: idx_ville1=0, idx_ville2=1, idx_ville3=2, idx_ville4=3, idx_ville5=4 et idx_ville6=5 ?
Non, voyez cela comme des index :
# ville de depart selectionnee par defaut
pcc[ville_dep][idx_dist] = 0
pcc[ville_dep][idx_select] = True
je suis désolée, je ne comprends pas
J'ai 6 villes et pour le moment il y'a 3 index, je ne vois pas ce que je dois mettre pour les 3 autres index
Vous avez un tableau de 6 lignes (et non 3 comme je l'ai indiqué) et 3 colonnes...
1 ligne par ville : 1 colonne pour le nom, 1 colonne pour la distance, une colonne pour la sélection.
ah d'accord, il n'y a donc besoin que de 3 index ?
de plus quand je teste ce code, voilà ce qu'il me renvoie:
>>> dijkstraDist(Matrice_Adj,"Lyon")
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "<tmp 1>", line 23, in dijkstraDist
pcc[depart][0] = 0
TypeError: list indices must be integers or slices, not strje ne comprends pas où est encore l'erreur
vous ne pouvez utilisez que des nombres pour accéder à un élément du tableau.
Pour utiliser des chaines de caractères, il faut traduire "Lyon" en 0 (zéro) au moyen d'un dictionnaire. Exemple:
dico_ville = {}
dico_ville["Lyon"] = 0
dico_ville["Paris"] = 1
etc.
Voilà ce que j'ai fais:
import numpy as np
Inf = np.inf
# on crée la matrice d'adjacence associee au graphe
Matrice_Adj= np.array([ [0,148,85,Inf,Inf,Inf], [148,0,157,148,Inf,Inf], [85,157,0,302,87,Inf], [Inf,148,302,0,253,167], [Inf,Inf,87,253,0,428], [Inf,Inf,Inf,167,428,0] ])
dico_villes={}
dico_villes["Roanne"]=0
dico_villes["Beaune"]=1
dico_villes["Lyon"]=2
dico_villes["Auxerre"]=3
dico_villes["Bourg"]=4
dico_villes["Paris"]=5
def dijkstraDist(G, depart):
# On récupère le nombre de sommets du graphe
N = np.size(G,0)
# Initialisation du tableau des plus courts chemins
# Le booléen pour savoir si le sommet a déjà été sélectionné
l_villes=["Roanne","Beaune","Lyon","Auxerre","Bourg","Paris"]
pcc=[[ville,Inf,False] for ville in l_villes]
idx_ville=0
idx_dist=1
idx_select=2
sommet_u = depart
dist_u = 0
pcc[depart][0] = 0
# Le premier sommet sélectionné est le sommet depart
pcc[depart][1] = True
# On compte le nombre de sommets sélectionnés
compteur = 0
while compteur != N-1:
# À chaque étape, la solution optimale doit être conservée (pour sélection du sommet correspondant à l'étape suivante)
minimum = Inf
# Étape de relâchement
for k in range(N):
# Si le sommet k n'a pas encore été sélectionné
if pcc[k][1] == False:
dist_uv = G[sommet_u][k]
# Distance totale du chemin s -> ... -> u -> v
dist_totale = dist_u + dist_uv
# Mise à jour du tableau des plus courts chemins
if dist_totale < pcc[k][0]:
pcc[k][0] = dist_totale
# Mise à jour de la solution minimale à cette étape
if pcc[k][0] < minimum:
minimum = pcc[k][0]
sommet_suivant = k
# On a traité complétement un sommet
compteur = compteur + 1
# Le sommet à traiter est sélectionné et d[u] est mis à jour
sommet_u = sommet_suivant
pcc[sommet_u][1] = True
dist_u = pcc[sommet_u][0]
return(pcc)
Maintenant, quand je teste, j'ai un nouveau problème:
>>> dijkstraDist(Matrice_Adj,2)
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "<tmp 1>", line 56, in dijkstraDist
sommet_u = sommet_suivant
UnboundLocalError: local variable 'sommet_suivant' referenced before assignmentModif :
def dijkstraDist(G, ville_dep) :
# nombre de villes ~ sommets du graphe
N = np.size(G, 0)
# liste des villes
l_villes = ["Roanne", "Beaune", "Lyon", "Auxerre", "Bourg", "Paris"]
# generation d'un dico index vs nom de la ville
dico_villes = {}
for i, ville in enumerate(l_villes) :
dico_villes[ville] = i
print " d_villes : %s\n" % dico_villes
# liste de liste des plus courts chemins
#
# nom de la ville
# distance parcourue
# status de selection
ll_pcc = [ [ville, Inf, False] for ville in l_villes]
print " ll_pcc : %s\n" % repr(ll_pcc)
idx_ville = 0
idx_dist = 1
idx_select = 2
# ville de depart selectionnee par defaut
ll_pcc[dico_villes[ville_dep]][idx_dist] = 0
ll_pcc[dico_villes[ville_dep]][idx_select] = True
print " ll_pcc : %s" % repr(ll_pcc)
commande d'entrée :
dijkstraPCC(Matrice_Adj, "Beaune", "Paris")
Au fait, ne vous inquiétez pas pour les l_, ll_, d_ etc.
J'utilise la notation hongroise... vieille habitude.
merci, mais quand je faisais tourner mon code original, j'avais ça :
>>> dijkstraDist(Matrice_Adj,2)
[[85.0, True], [157.0, True], [0, True], [302.0, True], [87.0, True], [469.0, True]]quand je fais tourner votre code, j'ai ça :
>>> dijkstraDist(Matrice_Adj,"Lyon")
d_villes : {'Roanne': 0, 'Beaune': 1, 'Lyon': 2, 'Auxerre': 3, 'Bourg': 4, 'Paris': 5}
ll_pcc : [['Roanne', inf, False], ['Beaune', inf, False], ['Lyon', inf, False], ['Auxerre', inf, False], ['Bourg', inf, False], ['Paris', inf, False]]
ll_pcc : [['Roanne', inf, False], ['Beaune', inf, False], ['Lyon', 0, True], ['Auxerre', inf, False], ['Bourg', inf, False], ['Paris', inf, False]]ça ne me renvoie plus les distances
Puis quand je teste dijkstraPCC entre Lyon et Paris, ca ne me renvoie pas le plus court chemin entre les 2:
>>> dijkstraPCC(Matrice_Adj,"Lyon","Paris")
d_villes : {'Roanne': 0, 'Beaune': 1, 'Lyon': 2, 'Auxerre': 3, 'Bourg': 4, 'Paris': 5}
ll_pcc : [['Roanne', inf, False], ['Beaune', inf, False], ['Lyon', inf, False], ['Auxerre', inf, False], ['Bourg', inf, False], ['Paris', inf, False]]
ll_pcc : [['Roanne', inf, False], ['Beaune', inf, False], ['Lyon', 0, True], ['Auxerre', inf, False], ['Bourg', inf, False], ['Paris', inf, False]]
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/emelinedevaud/Desktop/MPSI/TIPE/dijkstra TP8.py", line 61, in dijkstraPCC
ville = pcc[ville][2]
TypeError: 'NoneType' object is not subscriptableJe suppose que vous n'avez pas adapté votre code au changement index numérique / index alphanumérique ?
euh non ,c'est du chinois pour moi ça
voici mon code tel qu'il est sur Pyzo:
import numpy as np
Inf = np.inf
# on crée la matrice d'adjacence associee au graphe
Matrice_Adj= np.array([ [0,148,85,Inf,Inf,Inf], [148,0,157,148,Inf,Inf], [85,157,0,302,87,Inf], [Inf,148,302,0,253,167], [Inf,Inf,87,253,0,428], [Inf,Inf,Inf,167,428,0] ])
def dijkstraDist(G, ville_dep) :
# nombre de villes ~ sommets du graphe
N = np.size(G, 0)
# liste des villes
l_villes = ["Roanne", "Beaune", "Lyon", "Auxerre", "Bourg", "Paris"]
# generation d'un dico index vs nom de la ville
dico_villes = {}
for i, ville in enumerate(l_villes) :
dico_villes[ville] = i
print (" d_villes : %s\n" % dico_villes)
# liste de liste des plus courts chemins
#
# nom de la ville
# distance parcourue
# status de selection
ll_pcc = [ [ville, Inf, False] for ville in l_villes]
print (" ll_pcc : %s\n" % repr(ll_pcc))
idx_ville = 0
idx_dist = 1
idx_select = 2
# ville de depart selectionnee par defaut
ll_pcc[dico_villes[ville_dep]][idx_dist] = 0
ll_pcc[dico_villes[ville_dep]][idx_select] = True
print( " ll_pcc : %s" % repr(ll_pcc))
def dijkstraPCC(G, depart, arrivee):
pcc = dijkstraDist(G, depart)
# Reconstitution du plus court chemin
chemin = list()
# On reconstitue le plus court chemin d'arrivee vers depart
ville = arrivee
chemin.append(ville)
while ville != depart:
ville = pcc[ville][2]
chemin.append(ville)
# On demande le miroir de la liste obtenue pour que les sommets apparaissent dans l'ordre
return(list(reversed(chemin)))
non, mais j'avoue que j'ai des difficultés avec cette matière
et puis, je n'ai jamais utilisé les index
Bon, il y a un début à tout... pouvez-vous m'expliquer votre algo ? Du moins, ce qu'il est censé faire ? Ça m'aidera à faire du reverse engineering sur votre code...
alors, le but de mon algorithme est: une fois rentrés la matrice d'adjacence correspondant au graphe étudié, ainsi que la ville de départ et celle d'arrivée, l'algorithme renvoie le plus court chemin entre ces 2 villes (distance et ordre des villes par lesquelles on passe)
C'est pourquoi j'avais créé un premier programme qui permettait de renvoyer tous les plus courts chemins à partir d'une ville, puis un autre programme qui renvoyait le plus court entre 2 villes
Si j'ai bien compris, dijkstraDist() recherche toutes les distances minimales depuis une ville de départ vers toutes les autres villes ?
On utilise alors un attribut p(v) du sommet v contenant le poids du supposé plus court chemin menant de départ à v. Il est modifié au fur et à mesure de l'algorithme afin de contenir d(v) à la fin. A chaque étape on a : d(v)<=p(v)
Ensuite, il y'a le principe de relâchement qui consiste en un test permettant de savoir si on peut améliorer le plus court chemin jusqu'a v en passant par u. Cela revient à faire ce test: p(u)+d(u,v) < d(v) ?
Si oui, il faut corriger d(v).
si le test est négatif, on n'effectue aucune mise à jour
s'il est positif, cela signifie qu'il existe un chemin de plus petite taille pour aller de départ à v.
Alors: on passe de départ à u (ce chemin a le poids p(u) )
on termine ce chemin en utilisant l'arc (u,v) de poids d(u,v)
Il convient alors de faire :
p(v)<-p(u)+d(u,v)
A chaque étape, on sectionne le sommet tel qu'il n'a pas encore été choisi et tel que son attribut p soit le plus faible
Voilà, j'espère que j'ai été assez claire avec les notations...
Vous pouvez me donner un exemple ? Admettons que je parte de Roanne et que je veuille aller à Bourg-en-Bresse... les 2 seules villes accessibles sont Beaune et Lyon. Comment évoluent vos données ?
on part de rOANNE , donc on initialise d(roanne)=0 et pour les autres villes c'est +
Ensuite, n peut aller à Beaune ou à Lyon. On complète: p(roanne)+d(lyon,roanne)=85
p(roanne)+d(beaune,Roanne)=148
Ensuite on prend le plus petit des 2, ie Lyon et on regarde les villes accessibles depuis lyon, ie Beaune, Auxerre et Bourg. A chaque fois on additionne p(Lyon) avec d(Lyon,..) et on regarde si c'est plus petit , si oui on remplace, sinon on laisse la valuer d 'avant
Puis on regarde à nouveau la ville ayant le poids le plus petit parmi celles qui n'ont pas été sélectionnees, on regarde les villes accessibles , n fait le calcul .... on réitère le procédé jusqu'à ce que toutes les villes aient été choisies
Une question complémentaire...
On reprend l'exemple du trajet Roanne -> Bourg.
On a 2 choix : Beaune (148 km) et Lyon (85 km).
On choisit la plus petite distance => Lyon
Avec Lyon, on a 4 choix :
- Roanne (85 km) mais pas possible
- Beaune (157 km)
- Auxerre (302 km)
- Bourg (87 km)
On choisit la plus petite distance => Bourg
On s'arrête ou on vérifie qu'il y a d'autre(s) chemin(s) possibles pour ce trajet ?
Par exemple, Roanne -> Beaune -> Auxerre -> Bourg
D'apres Ce que j'ai compris de l'algorithme de Dijkstra, on s'arrete Car on veut le chemin le plus court ...
Bonjour bbomaths
je me suis repenchée sur mon code et j'ai toujours le même problème.
En fait, mon premier code
dijkstraDistMais sans bouleverser tout le code, si c'est faisable.
Idem pour mon code dijkstraPCC qui, je sais, ne fonctionne pas. je voudrais qu'on puisse rentrer la ville de départ et celle d'arrivée et qu'il retourne: le plus court chemin de Lyon à Paris est:
Vous comprenez? je n'ai pas vraiment envie de rechanger tout mon code, pour lequel j'y ai passé des heures ....
je vous remercie déjà de tout ce que vous avez déjà fait, et je vous remercie par avance de tout ce que vous pourrez éventuellement faire.
je vous souhaite une bonne journée
Bonjour bbomaths,
j'ai rajouté deux lignes de code dans dijkstraDist, afin qu'il renvoie la taille des plus courts chemins de depart à tout sommet v ainsi que le dernier sommet utilisé pour calculer cette taille.
Ainsi, mon code dijkstraPCC fonctionne et permet d'obtenir le plus court chemin de depart à arrivee., j'aimerais cependant qu'il renvoie aussi la distance .
Mon problème est cependant toujours le même pour les deux programmes: faire apparaitre le nom des villes
Bonne journée
j'ai oublié le code: les lignes modifiées sont en vert
import numpy as np
Inf = np.inf
# on crée la matrice d'adjacence associee au graphe
Matrice_Adj= np.array([ [0,148,85,Inf,Inf,Inf], [148,0,157,148,Inf,Inf], [85,157,0,302,87,Inf], [Inf,148,302,0,253,167], [Inf,Inf,87,253,0,428], [Inf,Inf,Inf,167,428,0] ])
def dijkstraDist(G, depart):
N = np.size(G,0) # On récupère le nombre de sommets du graphe
pcc = list() # Initialisation du tableau des plus courts chemins
for i in range(N):
pcc.append([Inf, False,None]) # Le booléen pour savoir si le sommet a déjà été sélectionné
sommet_u = depart
dist_u = 0
pcc[depart][0] = 0
pcc[depart][1] = True # Le premier sommet sélectionné est le sommet depart
compteur = 0 # On compte le nombre de sommets sélectionnés
while compteur != N-1:
# À chaque étape, la solution optimale doit être conservée (pour sélection du sommet correspondant à l'étape suivante)
minimum = Inf
for k in range(N): # Étape de relâchement
if pcc[k][1] == False: # Si le sommet k n'a pas encore été sélectionné
dist_uv = G[sommet_u][k]
# Distance totale du chemin s -> ... -> u -> v
dist_totale = dist_u + dist_uv
# Mise à jour du tableau des plus courts chemins
if dist_totale < pcc[k][0]:
pcc[k][0] = dist_totale
pcc[k][2] = sommet_u #pour se souvenir de quel sommet provient la modification
# Mise à jour de la solution minimale à cette étape
if pcc[k][0] < minimum:
minimum = pcc[k][0]
sommet_suivant = k
# On a traité complétement un sommet
compteur = compteur + 1
# Le sommet à traiter est sélectionné et d[u] est mis à jour
sommet_u = sommet_suivant
pcc[sommet_u][1] = True
dist_u = pcc[sommet_u][0]
return(pcc)
def dijkstraPCC(G, depart, arrivee):
pcc = dijkstraDist(G, depart) # Reconstitution du plus court chemin
chemin = list()
# On reconstitue le plus court chemin d'arrivee vers depart
ville = arrivee
chemin.append(ville)
while ville != depart:
ville = pcc[ville][2]
chemin.append(ville)
return(list(reversed(chemin))) # On demande le miroir de la liste obtenue pour que les sommets apparaissent dans l'ordre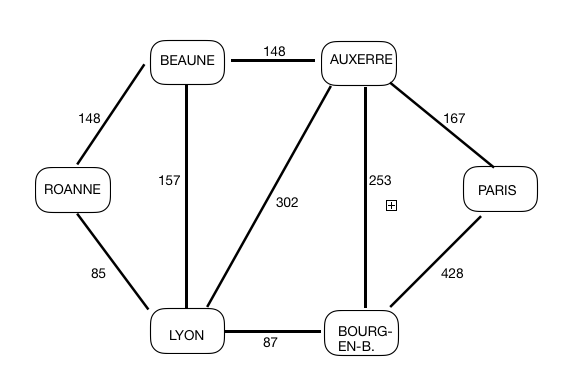
Bonjour,
Bonjour bbomaths,
j'ai rajouté deux lignes de code dans dijkstraDist, afin qu'il renvoie la taille des plus courts chemins de depart à tout sommet v ainsi que le dernier sommet utilisé pour calculer cette taille.
Ainsi, mon code dijkstraPCC fonctionne et permet d'obtenir le plus court chemin de depart à arrivee., j'aimerais cependant qu'il renvoie aussi la distance .
Mon problème est cependant toujours le même pour les deux programmes: faire apparaitre le nom des villes
Bonne journée
Je ne comprend pas très bien ce qu'il te manques ..
La distance depart -> arrivee est contenue dans pcc[arrivee][0]
Pour les noms, c'est un simple renommage de tes sommets, utilise une table de correspondance pour faire la traduction.
Ou alors j'ai pas compris ce que tu voulais

Bonjour
Vous avez tout à fait compris mais c'est justement le renommmage que je n'arrive pas à faire
Bonjour.
Je viens de tester mon algo utilisant numpy.
Il n'utilise que 2 tableaux :
- un tableau des distances minimales (1 x 6 float )
- un tableau des prédécesseurs (1 x 6 chaines de caractères ~ noms des villes)
Pour un parcours de Bourg vers les autres villes, il trouve :
trajet : Bourg -> Lyon -> Roanne -> 172.0 km
trajet : Bourg -> Lyon -> Beaune -> 244.0 km
trajet : Bourg -> Lyon -> 87.0 km
trajet : Bourg -> Auxerre -> 253.0 km
trajet : Bourg -> Auxerre -> Paris -> 420.0 km
Pour un parcours de Paris vers les autres villes, il trouve :
trajet : Paris -> Auxerre -> Beaune -> Roanne -> 463.0 km
trajet : Paris -> Auxerre -> Beaune -> 315.0 km
trajet : Paris -> Auxerre -> Lyon -> 469.0 km
trajet : Paris -> Auxerre -> 167.0 km
trajet : Paris -> Auxerre -> Bourg -> 420.0 km
Bonjour
Merci de votre réponse . C'est quelque chose comme ça que je veux qu'il affiche pour l'appel à dijkstraDist
Et je voudrais qu'il renvoie la même chose pour l'appel à dijkstraPCC
Comment avez vous fait ?
Je suis parti de votre code.
J'ai transformé vos deux tableaux indexés par des nombres en deux tableaux indexés par le nom des villes via un jeu de dictionnaires générés automatiquement à partir de la liste des villes et de la matrice d'adjacence. Une fois cette indexation alphabétique faite, je me suis aperçu que c'était plus simple de travailler à partir des noms des villes. Et comme j'avais les noms des villes et les distances inter-villes, ça n'a été que plus facile de basculer des noms aux distances et réciproquement. Du coup, on peut simplifier le code appelant puisque tout est accessible dans la même fonction.
L'utilisation de Numpy permet aussi de simplifier le traitement en utilisant quelques astuces.
Je peux vous envoyer le code par email (voir mon profil pour mon adresse) si vous voulez le tester. Il fait 450 lignes dont une moitié de commentaires et un quart de print de débogage en option.
Je suppose que vous utilisez Python 3.x ?

