Inscription / Connexion Nouveau Sujet
statistiques, covariance et coefficient de corrélation
Bonjour tout le monde,
Je me mélange un peu les pinceaux concernant les formules de covariance (probablement due à une confusion entre cov estimée sur échantillon vs celui de la population ?)
Je m'explique :
Lorsque dans les exercices on nous demande calculer le coefficient de corrélation linéaire R (= COV(XY)/SxSy), les données de l'énoncé me permettent très souvent de l'obtenir en appliquant « bêtement » R = SPExy/ racine de SCEx.SCEy
Seulement voilà, dans certaines questions isolées, il arrive que l'on ne me donne QUE les moyennes, écarts types et la somme des xiyi d'un échantillon annexe et dans la correction (assez succincte), ils utilisent la formule COV(XY) = (somme xiyi/ n) - mxmy, mais quand j'utilise cette formule, mon R est faux (car j'utilise
J'ai émis l'hypothèse que c'était parce que j'utilisais des écarts types estimés (calculés sur des questions situées plus haut avec n-1 ou donnés) et que cette formule de COV donnée était plutôt valide sur une population
Mais dans ce cas-là, quelle formule de COV utiliser avec "si peu" de données?
J'espère m'être fait comprendre, grosse confusion entre les différentes formules qui existent, erreur dans la correction ou mauvaise compression de ma part ?
Merci de m'avoir lue !
Du point de vue théorique, tu travailles avec une mesure de probabilité et pour toute variable aléatoire
-intégrable, l'espérance de
est par définition
. Ensuite, tu peux réécrire autrement cette intégrale grâce au théorème de transfert qui te permet d'intégrer sur les valeurs que prend
plutôt que sur l'univers abstrait
.
Par exemple, quand tu as une varieble de loi uniforme sur , tu as
et
Donc .
Ca c'est un exemple de calcul exact, avec une loi connue et facile.
Ce n'est pas toujours comme ça malheureusement, et en pratique tu ne connais pas la loi de X.
Cependant, tu es capable d'estimer l'espérance de n'importe quelle variable aléatoire intégrable grâce à des estimateurs statistiques. Par exemple l'estimateur de Monte-Carlo , où les X_i sont iid de même loi que X ; qui converge presque sûrement (ou en probabilité, ou en loi) vers
.
Tu as aussi des estimateurs de la variance, le TCL, etc... Je ne vais pas te faire un cours entier ici 
Plus tu prends N grand et meilleure est l'estimation, mais ce n'est pas tout. L'estimateur aussi peut être plus ou moins bon (biaisé, sans biais, erreur quadratique, etc).
Pour le reste, je ne comprends pas ta question, il y a des erreurs de typo non corrigées.
Merci beaucoup;
Avec deux petits exemples d'application, je serais peut être plus claire sur ce qui me pose problème :
Exemple 1:
A l?entrée dans la cohorte, on a mesuré la pression artérielle diastolique Pa des patients.
La moyenne obtenue chez les 30 patients ayant eu des complications est égale à 105 mmHg avec un écart type estimé de 10 mmHg.
Existe-t-il une corrélation linéaire entre la glycémie GL et la pression artérielle diastolique Pa chez les patients ayant eu des complications graves ? (risque ? 0,01). On donne 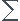 Pa
Pa GL= 28155. (En raison des effectifs des 2 groupes, on utilisera l?écart-type estimé.)
GL= 28155. (En raison des effectifs des 2 groupes, on utilisera l?écart-type estimé.)
Dans la correction , le coefficient de corrélation r est calculé de la façon suivante :
On note x = Pa et y=GL
Pour moi, cela donne une estimation biaisée... je ne comprends donc pas son utilisation
Exemple 2:
Et dans l'exercice suivant:
Pour vérifier la linéarité d'une méthode dosage, on prépare 6 étalons :
calcul de r par :
Je crois que mon incompréhension tient au fait que je n'arrive pas à comprendre l'égalité suivante (une notion doit m'échapper) : cf. image
** image supprimée **lire Q05 ![]() [lien] **
[lien] **

