Inscription / Connexion Nouveau Sujet
Statistiques inférentielles BTS
Bonjour,
Quand on cherche un intervalle de confiance pour une proportion, on considère la variable F qui suit la loi normale de paramètres p et racine carrée de (p(1-p)/(n-1)).
Pour le test de conformité d'une proportion, considérez vous que F suit la loi normale de paramètres p et racine de (p(1-p)/n) ou la loi normale de
paramètres p et racine de (p(1-p)/(n-1)) ?
J'ai vu des exercices à ce sujet traités de différentes façons, ce qui m'a fait douter ...
Merci d'avance !
salut
La loi d'échantillonnage de la fréquence est la loi normale de paramètres p et 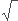 [p(1-p)/n].
[p(1-p)/n].
mais p étant inconnu, l'écart type est remplacé par son estimation ponctuelle [f(1-f)/n]*[n/(n-1)].
où f est la proportion obtenue dans ton échantillon

Bonsoir,
il me semble que quand on fait l'hypothèse nulle on connait
. Et donc l'écart-type est
.
À part ça on a déjà fait tellement d'approximations quand on arrive à ce stade du calcul qu'à mon avis il n'y a aucune différence entre les deux choix.
Merci de vos réponses.
Je vois que les avis sont finalement partagés ...
Certains considèrent qu'on connaît p à cause de l'hypothèse et
d'autres considèrent qu'on ne connaît pas p car, en effet, on ne le conaît pas ...
Un débat est lancé ...
Encore merci !
en fait le facteur [n/(n-1)] provient de l'estimation ponctuelle de l'écart type à l'aide de celui obtenu sur un échantillon de taille n
de rien
en général on ne connait pas p (puisqu'on le cherche) et l'estimation ponctuelle de p est f et on détermine un intervalle de confiance centré en f
En effet Carpediem ...
C'est ce que je pense, donc j'utiliserai le paramètre corrigé.
Bonne soirée !
Bonjour,
je reviens sur le sujet, un peu tard, mais je n'était pas disponible hier soir.
Quand on fait un test on suppose connue la valeur de p. C'est l'hypothèse nulle. Sous cette hypothèse la fréquence observée suis une loi normale d'écart-type et non
.
Pour ajouter un argument d'autorité, c'est l'avis de SAPORTA dans un livre de référence : Probabilités, analyse des données et statistiques.
Bonsoir,
Merci de cette nouvelle explication.
Je vais sans doute ajouter ce livre à ma bibliothèque.
Bonne soirée
il me semble que quand on fait une étude sur un échantillon extrait de la population on veut connaitre la proportion p de tel caractère ... donc on ne le connait pas.... (c'est l'objectif même des sondages)
la première approximation de cette proportion p est l'approximation ponctuelle de celle-ci donnée par la fréquence de ce caractère dans l'échantillon mais celle-ci n'ayant guère de sens on effectue une estimation par intervalle de confiance
et les seules données que nous ayons c'est la fréquence sur un échantilon (ou plusieurs) de m^me taille
par ailleurs il peut y avoir eu une estimation de cette proportion (à partir d'études antérieures ou sondage...)qui a donné la valeur P
la loi d'échantillonage de la fréquence étant connue (de façon théorique c'est la loi normale...)
on pose alors pour hypothèse nulle p=P puis on la vérifie avec l'échantillon que l'on possède
REM: si on connait la proportion exacte de la population (ou de la moyenne) pourquoi s'embêterait-on à l'estimer à partir d'un échantillon) et la stat inférentielle n'aurait plus lieu d'être....
dans le cas de test de validité d'hypothèse et en particulier dans le cas du contrôle de qualité on veut juste vérifier si cette moyenne ou cette proportion est égale à une certaine valeur fixée à l'avance
par exemple on reçoit un lot de N tiges de longueur théoriques L et à partir d'un échantillon de taille n on vérifie la conformité de ce lot par un test

d'ailleurs si on connaissait à l'avance la proportion il n'y aurait plus besoin d'aller voter et on ferait de grandes économies....

Bonsoir carpediem
Je dirais que tu n'as pas compris la situation.
Quand on fait un test il ne s'agit pas d'évaluer une valeur (intervalle de confiance) mais de savoir si le résultat observé est compatible (ou non) avec une hypothèse donnée.
C'est le même cas que ton exemple sur les longueurs de tiges. D'ailleurs on utilise des tests sur les proportions en contrôle de qualité.
Avec une remarque pratique :
dans ce cadre, pour n>100, il n'y a aucune différence pratique entre 1 et
tout à fait d'accord pour la remarque (mais le programme (et les examums) nous dit que....
pour ton post précédent oui et non et oui :
je croit qu'on (ou que je ) mélange 2 pb:
1: estimer une moyenne ou une proportion sur une poppulation à partir d'un échantillon (et un intervalle de confiance) (et plus l'échantillon est important plus l'estimation est exacte (l'idéal étant de prendre la ppulation en entier...)
2: comparer la moyenne ou la proportion d'une population à une valeur donnée à l'aide d'un échantillon de cette population et d'un test (qui est mon exemple)
mais je distingais bien ces deux choses dans mon premier post:
1: la loi déchantillonnage de la fréquence (et que tu donnes dans ton premier post)
2: le test avec comparaison à une valeur théorique "p" à partir des estimations faites sur un échantillon
quand on fait un sondage c'est bien pour déterminer la valeur inconnue de p et l'intervalle de confiance nous permet de dire que t% vont voter pour... à 
 t
t
la théorie nous dit simplement (grace au théorème de la limite centrée) que p suit telle loi
d'ac or not dac ?
Presque d'accord.
Quand on fait un test on n'est pas dans le même cas que quand on fait un intervalle de confiance.
Je prend un exemple de sondage sur les intentions de votes.
On peut vouloir connaitre deux choses :
-- Un intervalle de confiance sur la proportion de gens qui voteraient pour tel candidat : dans ce cas on utilise l'estimation de l'écart-type où p est la proportion observée.
-- Savoir si le résultat est compatible avec l'hypothèse : dans ce cas on utilise l'écart-type
Ceci étant dit je pense que la différence relève un peu du coupage de cheveux en 5 (à la règle et au compas).
En ce qui concerne le programme je ne voit aucune indication dans ce sens, et pour l'examen on demande en général des arrondis qui font disparaitre la différence (sur les proportions).
Une dernière chose : la v.a. F qui associe la proportion observée à un échantillon ne suit pas une loi normale. Elle suit une loi discrète (1/n) loi binomiale que l'on approche par une loi normale. Et je suis plus choqué par l'absence de correction de continuité que par la non correction de l'écart-type (qui, quoiqu'usuelle, est incorrecte car biaisée)
loi binomiale que l'on approche par une loi normale. Et je suis plus choqué par l'absence de correction de continuité que par la non correction de l'écart-type (qui, quoiqu'usuelle, est incorrecte car biaisée)
Ceci étant dit je pense que la différence relève un peu du coupage de cheveux en 5 (à la règle et au compas).
En ce qui concerne le programme je ne voit aucune indication dans ce sens, et pour l'examen on demande en général des arrondis qui font disparaitre la différence (sur les proportions).
Une dernière chose : la v.a. F qui associe la proportion observée à un échantillon ne suit pas une loi normale. Elle suit une loi discrète (1/n)loi binomiale que l'on approche par une loi normale. Et je suis plus choqué par l'absence de correction de continuité que par la non correction de l'écart-type (qui, quoiqu'usuelle, est incorrecte car biaisée)
tout à fait d'accord
et pour les correctifs je pense que cela vient de la difficulté crée chez les élèves d'ailleurs on donne souvent l'écart type pour le calcul d'un intervalle de confiance ou pour la mise en place d'un test
pour ce qui précède peut-être y a-t-il un pb de confusion : qu'est-ce que ton p dans :
....où p est la proportion observée.
si ton "p" est celui de l'échantillon et c'est ce que je viens de comprendre alors on est tout à fait d'accord
(j'appelais p la proportion dans la population)

