Inscription / Connexion Nouveau Sujet
Inférence statistique
Bonsoir.
Dans mon cours de statistique, il est question en première page d'inférence statistique et tout est flou, je n'y comprends rien.
Il est écrit très précisément :
''Soit une population décrite par un caractère représenté par la variable statistique X (valeur du revenu d'une population de ménages par exemple).
Dans cette population, s'il était possible de connaître la valeur Xi du caractère de l'individu i, et cela pour tous les individus, on serait alors en mesure de calculer les différentes caractéristiques de la variable statistique X de cette population : fonction cumulative, moyenne, écart-type, mode, médiane...
En particulier, on pourrait déterminer la fonction cumulative F(x) du caractère X : F(x)=Proportion des individus pour lesquels X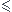 x
x
La variable statistique X dont on étudie les caractéristiques est alors une variable de statistique descriptive.
Si de cette population, on tire au hasard un individu, la valeur du caractère attaché à cet individu est une variable aléatoire X dont on peut déterminer la fonction de répartition car : P(Xx=Proportion des individus pour lesquels Xx=F(x)
La fonction de répartition de cette variable aléatoire est en fait la fonction cumulative de la variable de statistique descriptive X attachée au caractère étudié de la population.
Pour cette raison, pour cette variable aléatoire X, on parle de variable aléatoire parente X.
Lorsqu'un aléa est introduit (tirage d'un individu dans la population), on passe d'une variable de statistique descriptive à une variable aléatoire , ayant toutes les deux la même forme analytique pour la fonction cumulative.''
Voilà.
Je ne comprends rien à la formulation de ce cours.
Si je suis méthodiquement ce qui est dit :
On dit d'abord que si on connaissait toutes les valeurs du caractère X pour chaque individu, on pourrait calculer entre autres la fonction cumulative du caractère X. Bien.
Puis, que si on prend une personne de cette population, la valeur du caractère pour cette personne est une variable aléatoire X. Et c'est là que je bloque.
Si on tire une personne, avec l'exemple du salaire, son salaire X est connu, il n'y a plus rien d'aléatoire. Et normalement, c'est l'inverse, on utilise des individus dont on connaît tout pour déterminer les caractéristiques de la population dont on ne connait rien.
Donc je ne vois pas en quoi le salaire connu de la personne suivrait une VA.
Mais même si c'était le cas, je comprends très bien pourquoi P(Xx)=F(x). En effet, si l'on connaît tout de la population totale, et qu'il y a par exemple 10% des gens qui ont un salaire inférieur à 1500, il est logique que si l'on tire une personne au hasard dans cette même population, la probabilité qu'elle ait un salaire inférieur à 1500 est de 0,1.
Mais ce que je ne comprends pas c'est qu'on dise dans la suite que ''ce tirage d'individus équivaut au tirage d'un échantillon de n VA (X1, ..., Xn).''
Pourquoi dit-on que les individus que l'on tire ont une caractéristique qui suit une variable aléatoire ?
Normalement, quand on tire quelqu'un, on obtient une valeur déterminée de la caractéristique, sans aucune intervention de l'aléatoire.
Vous auriez un exemple concret pour m'expliquer tout ça ?
Sinon, j'aurai une autre question :
Qu'est-ce que l'information au sens de Fisher au point  et comment prouver que :
et comment prouver que :
I()=E[f'(x,)/f(x,)]² = E[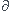 ln(f(x,))/]² ?
ln(f(x,))/]² ?
Merci !
Bonsoir,
pour donner un exemple : j'ai noté trois personnes sur internet.
À la première j'ai mis 5, à la seconde j'ai mis 3 et à la troisième j'ai mis 4,5.
On a alors une description totale de la population ( qui est très petite ).
On fait des statistiques descriptives sur cette population qui est entièrement connue.
Maintenant supposons que je tire au hasard une personne parmi ces trois.
La variable aléatoire associant sa note à chaque personne a exactement les mêmes caractéristiques que la statistique descriptive.

 statistiques en post-bac
statistiques en post-bac