Inscription / Connexion Nouveau Sujet
Mystere de l'information de fisher
Bonjour à tous,
J'ai toujours envie de comprendre la formule de l'information de Fisher, mais je n'ai pas encore atteint le but.
Sur Wikipédia, la recherche m'a renvoyer sur l'entropie de Shannon dont j'ai bien compris. J'ai compris sur ce dernier que, lorsqu'on a une source d'information et un récepteur de cet information. L'entropie mesure la quantité d'information nécessaire (manquante) qu'il faut pour que le récepteur puisse déterminer sans ambiguïté ce que la source émet. Ainsi lorsqu'une source émet toujours le meme symbole, il est claire qu'il faut zero(0) informations necessaire(manquantes) pour determiner sans ambiguité ce que la source emet. Ainsi l'enthropie est nulle. Mais si la souce emet par exemple deux symbole avec la meme proba il est claire qu'il ya confusion( la recepteur reste totalement confus de ce que va emettre la source), il lui faut 100% d'informations supplementaire (manquante) pour determiner sans ambiguité ce que va emettre la source. Ce ont des exemples de cas extreme. Ensuite dans le deuxieme exemple si on attribue plus de proba a un symbole, il est claire le recepteur va avoir tendence a pencher vers ce symbole (le predire) et donc l'enthropie dimunie.
Lorsqu'o dispose de N symbole distincts, par dichotomie (en prenant le cas N=2^n, puis generaliser) on trouve que le nombre de question (a reponse oui/non) que le recepteur doit poser a l'emetteur pour determiner sans ambiguité la valeur qu'emet la source est n=log2(N).
De là j'ai compris l'intervention de log dans la quantification de l'information qu'emet une source.
Cependant, concernant l'information de fisher je n'y parvient pas a savoir pourquoi on derive le log par "theta" qui esst le parametre. Mais je me suis donné une intuition, en me disant que c'est parce qu'on cherche uniquement l'information relatif a theta meme si je ne vois pas le lien entre "information relatif à theta" et "derivé le log par rapport a theta".
Le second point est que je ne comprend pas le fais d'élever cette dérivée au carré.
Merci d'avance !
Il y a des petites choses à clarifier avant. Les statisticiens ont un but, c'est à partir d'expériences (indépendantes et successives) suivant une loi de probabilité inconnue , de trouver une loi de probabilité concrète
qui approche
de façon satisfaisante.
Les statisticiens ne procèdent pas totalement au hasard. D'abord, ils observent les données, font des histogrammes, etc. Partant de là, ils réduisent les possibilités et se disent "tiens, ça ça a une bonne tête de loi normale, mais pour quels paramètres ?".
Ce faisant, ils se donnent une famille de paramètres (réels ou vectoriels), qui indexe une famille
de lois de probabilités. Le but est de trouver le
tel que
soit la plus fidèle possible à la vraie loi
, par définition inconnue.
En règle générale, le but est de modéliser par des lois simples, du type loi Normale, loi exponentielle, Bernoulli, etc, donc les lois sont à densité, qu'on nommera
. Presque à chaque fois, les lois sont les mêmes et ne diffèrent que par leurs paramètres. En particulier elles ont un support commun.
Une telle formulation mène n'importe quel mathématicien à essayer de se placer dans le cadre d'une minimisation ou maximisation de fonction. Parce que ça, on sait bien faire, en cherchant les zéros de la dérivée.
Les staticiens vont donc définir pour chaque loi une fonction
définie sur
par
, à valeurs dans
. S'il n'y a pas d'ambiguité, ils notent simplement
au lieu de
.
Je n'ai pas encore dit ce que sont les : ce sont simplement les résultats de n tirages successifs aléatoires selon la loi
inconnue. Ce réels/vecteurs sont fixés. Ce sont les données à disposition du statisticien.
On veut maximiser L parce que le point (quand il existe) où L atteint son maximum global est très vraisemblablement le point où tous les
ont des grosses valeurs. Si un paramètre
ne convient pas pour modéliser la loi
alors il va y avoir un
proche de 0 et donc la valeur du produit va s'effonder.
Si cela peut t'aider à voir pourquoi, souviens-toi que dans le cas d'une loi discrète, la densité n'est rien d'autre que
, i.e
quand X est de loi
.
Il est évident que
1) plus n est grand, et plus cette fonction L est adaptée (gros dataset : beaucoup de données)
2) L est à valeurs positives et le log est strictement croissant. Donc maximiser L ou revient au même
Tu préfères dériver un produit de n termes, ou une somme de n logarithmes ? Voilà l'intérêt principal de chercher à maximiser à la place de L, les calculs sont bien plus simples !
Mais revenons à nos moutons. L est appelée la fonction de vraisemblance. s'appelle la log-vraisemblance.
Le optimal (quand il existe) est généralement tel que
, et est appelé le maximum de vraisemblance (ou de log-vraisemblance).
Sachant cela, la mission du statisticien se trouve grandement simplifiée. Pour approximer , il lui suffit de construire un estimateur du maximum de (log-)vraisemblance, et de sélectionner une loi
avec un
le plus proche possible de
et ça fera l'affaire. Mais à quel point cette loi fait-elle l'affaire, en fait ?
Si on a trouvé un paramètre tel que
colle bien aux données (les
), comment cela se généralise-t-il à n'importe quelles données issues de la loi
?
Si on prend , et qu'on note
.
Maintenant (il faut l'écrire plus rigoureusement, mais ça fait déjà un beau pavé là)
si et
est "proche" de f alors le rapport des deux est proche de 1 et donc notre intégrale est proche de
presque-sûrement.
C'est peu rigoureux (en particulier parce que la convergence presque sûre n'est pas métrisable) mais ça veut dire que si est très proche de
alors
est très proche de 1. Je n'entre pas plus dans les détails. Pour que tout fonctionne bien, il faut des hypothèses sur la façon dont les lois
varient avec
, notamment.
Le niveau suivant d'étude, c'est de regarder non plus l'espérance conditionnelle, mais à quel point cette dernière est proche de zéro, pour savoir à quel point il faut que soit proche de
(et
de
) pour être satisfait. Ca, ça s'appelle la variance et c'est ce qui explique pourquoi on se retrouve à calculer des carrés : Var(X) = E(X²) - E(X)² = E(X²) quand E(X) = 0

Il se trouve que l'information de Fischer est justement à quelques détails près la variance de dl/d\theta(X) avec les notations de notre petit calcul
Merci beaucoup, comme vous expliquez bien !
J'ai bien compris. l'EMV étant une variable aléatoire fluctue autour de la valeur de thêta qui maximise la vraisemblance en fonction des l'observations issues de l'échantillon. C'est pourquoi on observe la variabilité de thêta autour de l'EMV.
Je viens de voir une vidéo où on l'explique de la manière suivante:
On trace la courbe de la log de vraisemblance. Si la courbe est trop aplatie la variabilité de thêta ne l'éloigne pas trop du maximum. Par contre si elle est pique, une petite variation de theta nous eloige du maximum. Cependant , l'aplatissement d'une courbe est lié aux moments d'ordre 4 et ici on pris le moment d'ordre 2 ?
Pouvez-vous m'expliquer plus claire dans ce cas.
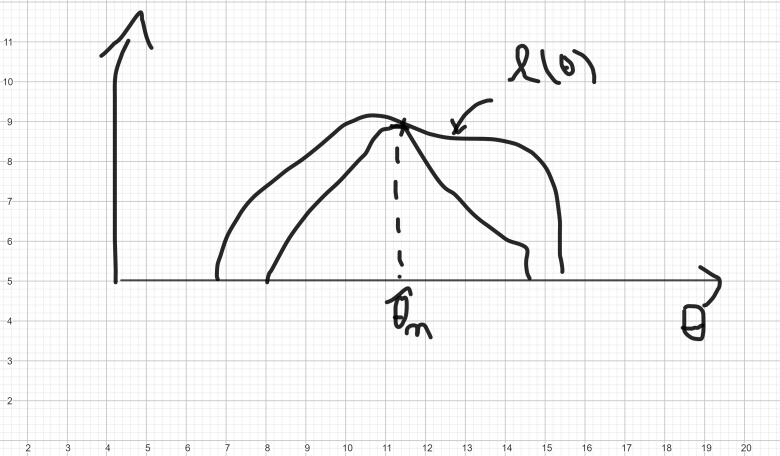
Un aplatissement de la courbe, ça veut seulement dire que la fonction ne varie pas beaucoup si on perturbe theta dans une directetion. Ici c'et un aplatissement en 2D donc par "direction" on veut simplement dire ajouter ou retirer un petit réel à .
Mais si appartient à
par exemple et si tu as une surface dans
avec un plat ça veut dire que ton estimation (en cote) reste tout aussi valable si tu perturbes
suivant l'axe des abscisses ou celui des ordonnées.
Si tu es sur un pic, ça veut dire que tous les travaillent de concert à l'établissement d'une valeur, et que si jamais tu modifies un tout petit peu
alors tu auras un ou plusieurs
qui vont devenir très faibles et faire chuter la valeur du produit, sans que cela ne soit compensé par une augmentation de
pour un autre
par rapport à
.
Ce raisonnement est pertinent parce que les sont à valeurs dans [0,1]. Admettons qu'on passe de
à
et que tous les f(x_k) restent inchangés sauf
et
* passe de 0.75 à 0.60
* était à 0.85 et vaut maintenant h
Pour que le produit ne change pas de valeur, il faut que ne change pas de valeur. Ca veut dire
, i.e
. C'est impossible, cette valeur est plus grande que 1!
Si chute peu, alors cette chute est compensable par une (ou plusieurs) augmentation des autres
.
Mais si l'un (au moins) des chute trop vite (ici, la chute est de 0.15, soit 20%) alors les compensations devront être bien plus importantes que ce dont a chuté
, avec en plus la contrainte de ne pas pouvoir passer au dessus de 1.
-------
Pour cette histoire de moments d'ordre 4, je pense que tu fais référence au kurtosis mais c'est un autre sujet qui n'est pas spécifiquement lié à notre histoire d'information de Fischer

 statistiques en post-bac
statistiques en post-bac