
 statistiques en post-bac
statistiques en post-bac
- Ensemble et application Partie II
- Équations différentielles : un Cours complet avec des exemples
- Espaces vectoriels et Applications linéaires - supérieur
- Un best-of d'exos de probabilités (après le bac)
- Généralités sur les matrices, applications linéaires, changement de base, rang d'une matrice - supérieur
Inscription / Connexion Nouveau Sujet
Accueil l'île des mathématiques Forum de mathématiquesListe de tous les forums de mathématiques SupérieurOn parle exclusivement de maths, pour le supérieur principalement, les BTS, IUT, prépas... Maths sup StatistiquesTopics traitant de statistiques [tout]Lister tous les topics de mathématiques
Niveau Maths sup
Tri de points
Posté par Lollesque
Bonjour,
je travaille actuellement sur mon TIPE, et je suis confronté à un petit problème de tri de données...
Je vais essayer d'être clair: J'ai un tableau de données (sous matlab):
colonne 1 = mes valeurs
colonne 2 = numérotation associée (pour afficher la courbe y=f(x))
Les valeurs que j'ai oscillent peu autour d'une moyenne, sauf aberrations qui sont facilement repérables. Je cherche une méthode pour trouver de façon un peu grossière la valeur moyenne, ce qui permet ensuite d'éliminer les points aberrants puis de calculer de manière plus précise la valeur moyenne.
Mon idée pour trouver une première approximation de la valeur moyenne et calculer la moyenne des valeurs qui apparaissent le plus de fois dans le tableau (avec un outil comme la variance ou l'écart type??)... Mais je ne sais absolument pas comment faire (je n'y connais pas grand chose en statistique)...
Je vous envoie une petite image (excusez le format timbre poste, mais j'ai eu du mal a obtenir 60Ko) pour illustrer mes explications, en bleu les points et en rouge une régression linéaire de ces points...
Rmq: Je peux déja supprimer la partie droite de la courbe, mais comment repérer à partir de quel point faut-il enlever des valeurs?
Merci d'avance pour votre aide.
(au fait, comment choisit-on niveau "maths spé"?? (je n'ai que "maths sup" et "bts/iut" dans le menu déroulant en bas...)
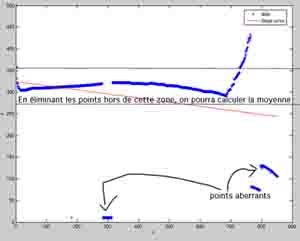

J'ai essayé en récupérant les points qui avaient un écart à la moyenne inférieur à 10% de l'étendue des mesures... c'est pas mal, mais il me reste les points de droite qui ne sont pas éliminés...
D'autres idées???