



 probabilités en post-bac
probabilités en post-bac
- Un best-of d'exos de probabilités (après le bac)
- Équations différentielles : un Cours complet avec des exemples
- Ensemble et application Partie II
- Ensemble et application Partie I
- Espaces vectoriels et Applications linéaires - supérieur
- Généralités sur les matrices, applications linéaires, changement de base, rang d'une matrice - supérieur
Inscription / Connexion Nouveau Sujet
Accueil l'île des mathématiques Forum de mathématiquesListe de tous les forums de mathématiques SupérieurOn parle exclusivement de maths, pour le supérieur principalement, les BTS, IUT, prépas... ProbabilitésTopics traitant de probabilités [tout]Lister tous les topics de mathématiques
Niveau Prepa (autre)
Probabilité
Posté par simon49460
Salut à tous,
Besoin d'un peu d'aide pour cet exo. Merci de votre réponse. (Bonne année)
On veut estimer le diamètre moyen de pièces circulaires d'un lot qui comporte 413 pièces. Selon des résultats antérieurs, on admet que l'écart-type du diamètre serait vraisemblablement 0,35 cm et que la distribution des diamètres est gaussienne. Déterminez le nombre de pièces que l'on doit prélever du lot pour obtenir, avec un niveau de confiance de 95%, une estimation du diamètre moyen des pièces avec une marge d'erreur n'excédant pas 0,023 cm.
Bonjour,
Si l'écart-type sur le diamètre d'une pièce est 0,35, quel est l'écart-type sur la moyenne des diamètres de n pièces ?
Rebonjour,
Votre message ne m'aide pas tant que ça.
Mon énoncer s'arrête ici je n'est pas plus d'information.
Serait il possible d'avoir des réponses ou des éléments de réponse à ce sujet merci.
Bonne soirée.
Rebonjour,
Votre message ne m'aide pas tant que ça.
Mon énoncé s'arrête ici je n'ai pas plus d'informations.
Serait il possible d'avoir des réponses ou des éléments de réponse à ce sujet merci.
Bonne soirée.
La question que je te pose, ce n'est pas une demande d'information supplémentaire. C'est quelque chose que tu devrais savoir faire, si tu maîtrisais bien ton cours.
Soit une suite de variables aléatoires indépendantes et identiquement distribuées (ici, les
sont les diamètres des pièces produites et leur distribution est gaussienne d'écart-type 0,35).
Que peut-on dire de la distribution de la moyenne ? Quel est son écart-type ?
Ça te permettra de savoir le qui convient pour connaître le diamètre moyen des pièces avec une marge d'erreur de 0,023 avec un niveau de confiance de 95%.
À toi de jouer.
Bonjour,
Pour répondre à votre question à la place de Simon, je dirais que l'écart type de la distribution de la moyenne vaut l'écart-type/sqrt(n). Mais j'aurais une autre question car dans la formule de calcul de la marge d'erreur, elle ne fait pas référence aux 413 pièces qu'il faut utiliser. A quel moment devons nous utiliser cette valeur dans nos calculs.
Cordialement,
Oui, tu as raison, j'oubliais que ce qui est demandé est d'estimer le diamètre moyen des 413 pièces. Ce qui nous intéresse est donc
Donc dans la formule on remplace sigma/sqrt(n) par (sigma/sqrt(n))-(sigma/sqrt(413)) si j'ai bien compris.
Non, on remplace par l'écart-type de la variable aléatoire qui figure à la dernière ligne de mon précédent message et ce n'est pas l'expression que tu donnes.
La variance de la moyenne dans un échantillon pour un tirage sans remise mais là nous n'avons pas de prélèvement d'échantillons dans une population si on regarde l'énoncé
Ah mais si il s'agit d'un tirage sans remise, puisqu'ils nous demandent de trouver le nombre de pièces que l'on doit prélever dans le lot
Bon, ça ressemble à ce qu'on a au final avec . Il s'agit de calculer la variance de
où les sont indépendantes de variance
. Ce calcul se fait assez facilement en utilisant ce qu'on sait sur la variance d'une somme de v.a. indépendantes.
Du coup, est-ce que la formule que je vous ai proposé précédemment est la bonne ou alors il faut faire le calcul de la variance de l'expression que vous venez de donner?
Bonjour,
En fait, lorsqu'il n'y a pas remise et c'est généralement le cas lorsqu'on choisit un échantillon, les variables aléatoires ne sont pas indépendantes.
Quand l'échantillon est petit par rapport à la population, on s'en fiche mais lorsque le taux de sondage (c'est à dire la proportion de la population introduite dans l'échantillon) est supérieur à 5% ou 10% on corrige la variance de la moyenne par un facteur d'exhaustivité. Cela règle en partie le problème.
La formule que tu as donné ShooTinG est correcte, contient cette correction et ne nécessite pas de démonstration à ton niveau, il te reste à l'appliquer pour un intervalle avec une confiance de 95%.
PS : ce qu'il y a derrière c'est la même chose qu'approximer une loi hypergéométrique par une loi binomiale.
Je ne comprends plus rien. Dois-je utiliser la formule que je viens de donner ou alors avec le calcul de GBZM?
Vassilia, peux-tu me dire pourquoi les diamètres des 413 pièces du lot ne sont pas des variables aléatoires indépendantes ?
Je vais donc appliquer la formule de mon cours car nous n'avons pas vu la forme avec N au lieu de N-1.
J'étais en train de commencer ca 
** image supprimée **
* Modération > Les images de recherches ne sont pas autorisées sur l'île.
Par ailleurs, ce brouillon était illisible et risquait de causer un torticolis aux aidants *
La formule que tu as donné suffira bien mais GBZM ne pouvait pas deviner que tu l'avais dans ton cours.
Les diamètres des 413 pièces sont bel et bien des variables aléatoires indépendantes si on fait les suppositions qui vont bien sur la ou les machines qui fabriquent les pièces, jusque là tout va bien.
Le problème c'est que quand on prend les n pièces utilisées dans l'échantillon, si on ne les remet pas au fur et à mesure, on ne pioche pas dans les 413 pièces à chaque fois donc les utilisés dans l'échantillon ne seront plus vraiment indépendantes.
Exagérons volontairement pour comprendre, on prend un échantillon de 413 pièces sans remise, on va calculer la valeur exacte de la moyenne dans la population, on peut recommencer l'expérience autant de fois qu'on veut, ça ne changera rien si ce n'est l'ordre de tirage. La variance est nulle.
Maintenant prenons un échantillon de 413 pièces avec remise, on sent bien que si on recommence l'expérience, on n'aura pas toujours la même valeur pour la moyenne calculée dans l'échantillon, la variance est juste divisée par 413 ce qui est déjà pas mal.
ShooTinG, tu peux continuer ton calcul sans te soucier de la discussion entre Vassilia et moi.
Mais Vassilia, je ne comprends pas le troisième paragraphe de ton message sur la non-indépendance des . Si les 413
sont indépendantes, les
qu'on prend parmi elles sont indépendantes, non ?
Et la justification que tu donnes dans ton 4e paragraphe ne me convainc pas du tout. En supposant l'indépendance, je trouve bien aussi que la variance est nulle si .
Qu'est-ce qui ne va pas dans mon calcul ?
En fait, on ne parle pas de la même chose mais j'ai peur qu'on perde un peu ShooTinG en route.
Au début première suite de variables aléatoires : on produit des pièces selon une loi normale de moyenne et d'écart type
, là d'accord on a indépendance entre les
.
Toi tu continues à travailler avec comme une surpopulation et
un échantillon simple donc ce que tu fais est parfaitement valable.
Tu trouves , je suis d'accord.
Appelons la variance qui utilise la correction de Bessel (c'est quand on divise par
au lieu de
pour le calcul de la variance) et
la variance sans cette correction.
Toi tu vas bien sur utiliser l'estimateur sans biais obtenu à partir de et pour estimer tu utiliseras donc
On peut voir les choses autrement, la moyenne sur l'ensemble de la population des 413 pièces, elle est fixée, elle ne peut plus bouger.
On étudie une deuxième suite de variables aléatoires qui est donc cette fois un échantillon exhaustif où on choisit à chaque fois une pièce parmi les 413 pièces déjà produites.
Maintenant, sachant que le premier tirage est fait, la moyenne dans la population restante, elle change, il faut la recalculer sur les 412 pièces restantes puisque la pièce tirée en 1 a disparue de la population. C'est en cela que je dis qu'il n'y a pas indépendance.
Essayons de retomber sur nos pattes, dans ce contexte, ce qu'on va utiliser, c'est car nos 413 pièces représentent la population. Mais heureusement, on a
Donc pour estimer, on fera et on trouve bien la formule donnée par ShooTinG.
Ta version est plus naturelle je trouve et sans doute plus propre mathématiquement parlant mais en règle général en stats, on apprend qu'on multiplie par le facteur qui va bien et on ne fait pas trop dans les détails, je ne suis même pas sure que la notion d'estimateur sans bais soit au programme de Shooting. Déjà que certains sont laxistes entre et
pour estimer une variance à partir d'un échantillon, j'aime autant te dire que entre
et
...
Pour répondre à votre question Vassillia, nous avons vu en théorie la notion d'estimateur sans biais, convergent... Et nous avons appris comment les retrouver avec la méthode de vraisemblance. Mais il est vrai que pour le calcul de la variance on voit un peut de tout. En tout cas, il me semble que quand il s'agit d'un échantillon il faut utiliser n-1
Il te semble bien, tu peux faire tes calculs tranquillement, dis nous si tu t'en sors 
Juste pour le fun, je fais une démonstration pour GBZM qui passe par les variables non indépendantes (je n'ai jamais prétendu que c'était rentable pour la démo)
Avec une population de taille , de moyenne
et de variance
, où chaque élément peut prendre des valeurs
pour
.
Soit le nombre de fois que la valeur
apparaît dans la population, de sorte que
On prend l'estimateur classique
On a donc
Bien sur si les sont indépendantes car remise, la vie est belle, et on retrouve la formule habituelle
si
mais sinon ça se complique
et
Il faut séparer le cas où donc on va utiliser les probabilités conditionnelles
si
car l'effectif
a diminué en même temps que l'effectif de la population
ou si
car l'effectif de la population a tout de même diminué
On arrive donc à
Mais on a par définition autrement dit
Et de même autrement dit
On remplace tout ça
pour avoir notre covariance
Et enfin pour avoir notre variance
Et voilà, le fameux est apparu !
Bonjour, pour ce problème j aurais vu une réponse toute simple tirée d un intervalle de confiance à 95%.
La loi suivie pour un échantillon de taille n est une loi normale de paramètres 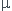 et d'écart type
et d'écart type  /
/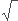 n
n
I=[ -1.96/n, 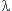 +1.96/n]
+1.96/n]
Avec ici 1,96/n=0.023. reste à déterminer n.
salut,
@flight
c'est aussi ce que je pensais mais n depasse alors la taille de la population (le lot).
Peut etre une erreur dans l'enonce ?
L'énoncé est parfaitement correct mais il faut corriger avec le facteur d'exhaustivité qu'on appelle aussi facteur de correction pour population finie voir ![]()
En théorie, il faudrait le faire systématiquement lorsqu'il n'y a pas remise mais en pratique quand n est très petit devant N, on peut s'en passer sans que les résultats soient impactés puisque ce facteur est alors très proche de 1.
La discussion entre GBZM et moi était pour savoir d'où vient ce coefficient, elle n'est pas indispensable pour résoudre l'exercice, pas de panique.
Merci Vassilia pour ces explications.
J'en retiens (je suis assez têtu) que ce n'est pas une question d'indépendance de variables aléatoires, mais que la différence (très mince !) entre le et le
vient du fait de savoir si on prend pour la variance
- soit la variance de la loi donnée a priori (ce que semble suggérer l'énoncé, puisqu'il parle des "résultats antérieurs")
- soit la variance estimée à partir de l'échantillon de taille .
Je vois que flight et alb sont tombés dans le piège pourtant mis en évidence par ShooTing ici :![]() Probabilité
Probabilité
Ton bilan sur N et N-1 me convient tout à fait.
En fait, cette histoire d'indépendance, je n'en ai pas parlé pour toi, j'en ai parlé pour que ShooTing comprenne pourquoi on fait apparaître un facteur d'exhaustivite sans plus d'explication. C'est vraiment l'erreur fréquente qu'il avait fait lui mais aussi flight et alb précédemment.
A mon avis, ni ton raisonnement ni le mien n'est exigible mais je t'ai quand même fait la démo qui correspond à son cours pour te convaincre que parler d'independance ou non a du sens comme je sais bien que tu es têtu
Bonsoir Vassilia,
Je reviens sur ton deuxième calcul. On peut le faire sans proba, uniquement algébriquement.
On se donne réels
,
, tels que
. Par conséquent
.
Notons, pour de cardinal
,
. Alors :
D'où l'on déduit le rapport entre les variances des et des
(la somme des
est bien sûr nulle) :
Une petite simulation en python ....
Si on veut une marge d'erreur n'excédant pas 0.023 avec niveau de confiance 95%, il nous faut un écart-type d'en gros 0.0117.
On tire un lot de N=413 valeurs suivant une loi normale d'écart type 0.35. On prend pour échantillon les n=282 premières valeurs. On calcule la différence entre la moyenne du lot et la moyenne de l'échantillon.
On fait ça p=10000 fois, et on calcule l'écart-type des 10000 différences :
import random as rd
import numpy as np
def diffmoy(N,n,mu,sigma) :
Lot=[rd.gauss(mu,sigma) for i in range(N)]
moylot = np.mean(Lot)
moyech = np.mean(Lot[:n])
return moyech-moylot
def ectypdiff(N,n,mu,sigma,p) :
DM=[diffmoy(N,n,mu,sigma) for i in range(p)]
theo = sigma*np.sqrt((N-n)/N/n)
print("écart-type : {:.5f}; écart-type théorique : {:.5f}"\
.format(np.std(DM),theo))Un essai :
ectypdiff(413,282,20,0.35,10**4)écart-type : 0.01164; écart-type théorique : 0.01174
Maintenant, avec un lot 10 fois plus important, soit 4130, et un échantillon de 732 (on ne répète que 1000 fois) :
ectypdiff(4130,732,20,0.35,10**3)écart-type : 0.01191; écart-type théorique : 0.01173
Bonsoir GBZM,
C'est pas faux, c'est même très joli comme manière de faire.
Je suis partie sur un calcul avec proba car pour moi, la différence entre tirage avec ou sans remise de son cours évoque vraiment ce type d'argument mais on peut présenter les choses autrement, je ne suis pas contre, bien au contraire.
Je ne sais pas ce que tu en penses, je trouve que l'explication très intuitive relative à l'indépendance que j'ai faite à ShooTinG au tout début peut aider un étudiant à visualiser le problème, en tout cas il a eu l'air de comprendre d'après sa réponse. Ceci dit, je suis très biaisée par mes habitudes d'enseignement avec un public bien particulier donc mon ressenti n'est pas forcément pertinent et tu auras peut-être un avis différent.
Je pense deviner pour qui tu fais cette simulation, quand tu dis que tu es tetu, tu ne plaisantes pas...
J'ai prolongé ma simulation pour bien faire voir la différence qu'il y a entre
- utiliser la moyenne de l'échantillon pour estimer la MOYENNE DU LOT (ce qui est demandé dans l'exercice) et
- utiliser la moyenne de l'échantillon pour estimer l'ESPÉRANCE DE LA LOI (ce que veulent faire flight et alb12).
La simulation porte sur 10000 lots de 413 valeurs tirées selon une loi normale d'espérance 20 et d'écart-type 0.35, les échantillons consistant en les 282 premières valeurs de chaque lot. Voici ce que ça donne :
La différence entre moyenne de l'échantillon et moyenne du lot est en dessous du seuil de 0.023 dans 9455 cas sur 10000.
La différence entre moyenne de l'échantillon et espérance de la loi (20) est en dessous du seuil de 0.023 dans 7242 cas sur 10000
j'ai eu en effet une interpretation trop simpliste de l'exercice
la demi longueur de l'intervalle de confiance est 1.96*0.35/sqrt(n)
on resout 1.96*0.35/sqrt(n)=0.023 soit une taille improbable de 890
je corrige l'enonce en remplaçant 0.023 par 0.23 pour obtenir une taille de 9
La taille de la population est alors au moins 10 fois celle de l'echantillon, la problematique avec/sans remise tombe
@simon49460
Peux tu donner suite à ton message ?
Peux tu preciser de quelle "autre" prepa il s'agit ?
As tu eu un corrige de cet exercice ?
Euh oui mais non, c'est de la triche, tu ne peux pas changer l'énoncé parcequ'il est trop difficile. Au vu de son cours, il est certain que la problématique avec ou sans remise est au programme.
Comprends-tu ce que GBZM et moi essayons d'expliquer ? Dans un sens l'espérance de la loi est la moyenne d'un lot de taille infinie et dans ce cas le coefficient d'exhaustivité vaut 1 ce qui te permet d'utiliser la formule "simpliste" dont tu parles.
alb12, si tu veux connaître exactement la moyenne des diamètres d'un lot de 413 pièces, de manière certaine, c'est facile : tu prends comme échantillon la totalité des pièces.
Tu pourras donc assurément avoir cette moyenne dans une marge d'erreur de 0.023 avec niveau de confiance 95% en prenant un échantillon plus petit !
La taille de l'échantillon, on la calcule avec le résultat de cours donné par ShooTinG.
d'accord avec tout ce que vous dites
j'avais juste au depart une reserve sur le caractere irrealiste de l'exercice
pour un lot de 413 pieces on pourrait raisonnablement prevoir un echantillon test de 10/15 pieces
c'est pourquoi je pariais sur un enonce errone
mais j'avais certainement tort puisque simon49460 n'intervient plus
Citation :
j'avais juste au depart une reserve sur le caractere irrealiste de l'exercice
j'avais juste au depart une reserve sur le caractere irrealiste de l'exercice
Bah, on trouve souvent des habillages "concrets" d'exercice mathématique nettement plus irréalistes.
En tout cas, le nombre de pièces du lot joue un rôle fondamental dans l'énoncé. Moi-même je ne m'en étais pas aperçu dans un premier temps et je prenais à tort l'exercice de la façon dont flight l'a pris, avant de réaliser grâce à l'intervention de ShooTinG qu'il fallait prendre en compte le nombre de pièces du lot.