
 autre en post-bac
autre en post-bac
- Équations différentielles : un Cours complet avec des exemples
- Généralités sur les matrices, applications linéaires, changement de base, rang d'une matrice - supérieur
- Ensemble et application Partie II
- Un best-of d'exos de probabilités (après le bac)
- Espaces vectoriels et Applications linéaires - supérieur
Inscription / Connexion Nouveau Sujet
Accueil l'île des mathématiques Forum de mathématiquesListe de tous les forums de mathématiques SupérieurOn parle exclusivement de maths, pour le supérieur principalement, les BTS, IUT, prépas... Maths sup AutreTopics traitant de autre [tout]Lister tous les topics de mathématiques
Niveau Maths sup
TIPE moteur de recherche sonore
Posté par cotedor
Bonjour à tous,
Nous devons créer un moteur de recherche sonore et nous aurions besoins de quelques orientation de travail pour parvenir à le créer. Plus précisément, ce serait une sorte de Shazam, mais pour tous les sons existants, et qui nous renverrait sur toutes les pages web en rapport avec le son proposé. Nous savons déjà que nous devons trier les sons d'après leurs fréquences, nous pensons a la transformation de Fourier, mais ne savons pas vraiment si cela serait le plus judicieux pour la classification de nos sons, il se peut qu'elle ne soit pas assez précise. En effet notre but est d'identifier un son spécifique.
Exemple : si nous lui faisons écouter le bruit d'un oiseau, il faudrait que le moteur de recherche nous donne l'espèce de l'oiseau et non simplement nous dire que c'est un oiseau, pour par la suite nous rediriger vers les pages le concernant.
Auriez-vous quelques idées qui pourraient affiner notre projet ?
Merci d'avance !
Citation :
Exemple : si nous lui faisons écouter le bruit d'un oiseau, il faudrait que le moteur de recherche nous donne l'espèce de l'oiseau et non simplement nous dire que c'est un oiseau
Petit détail sur la forme : C'est un TIPE, pas un projet de recherche abouti Exemple : si nous lui faisons écouter le bruit d'un oiseau, il faudrait que le moteur de recherche nous donne l'espèce de l'oiseau et non simplement nous dire que c'est un oiseau
 . Tu peux te donner cet exemple d'objectif pour poser les enjeux du projet... Mais tu ne seras pas en mesure de le réaliser vraiment dans le cadre du TIPE. Au mieux tu pourras faire une expérience sur un périmètre restreint et dans des conditions qui te seront favorables.
. Tu peux te donner cet exemple d'objectif pour poser les enjeux du projet... Mais tu ne seras pas en mesure de le réaliser vraiment dans le cadre du TIPE. Au mieux tu pourras faire une expérience sur un périmètre restreint et dans des conditions qui te seront favorables.
Sinon, le sujet est absolument génial en soi, et permet de très nombreuses pistes de recherche... et d'usages novateurs assez passionnants
.
Une première réaction globale :
Il va falloir effectivement trouver une représentation des sons qui soit exploitable (fréquences, mais pas que... évolutions dans le temps...).
Il y a un gros travail à faire en amont pour établir un modèle de son qui réduise la quantité de données, et qui mette en évidence les propriétés caractéristiques du son qui permettront ensuite de discriminer la nature des sons.
Ensuite il te faut un procédé d'apprentissage.
Pour cela, l'approche classique consiste :
- à mettre en place une base de sons,
- à lui appliquer la représentation que tu penses la plus appropriées (celle ci évoluera avec le temps et la connaissance qui découlera de tes travaux ou des références que tu trouveras dans la communauté scientifique),
- à "instruire" cette base en rentrant toi-même les informations que tu détiens sur ces sons (et que tu voudras reconnaître par la suite),
- à élaborer un modèle d'apprentissage, par régression, réseau de neurones, arbre de décision, ou tout procédé statistique ou de "machine learning" susceptible d'apprendre,
- à tester, valider, comparer ces différentes méthodes et algorithmes d'apprentissage selon leur efficacité.
La richesse de cette base d'apprentissage, et l'adéquation de la représentation sonore choisie seront les meilleurs atouts pour réussir un projet de cette ambition. Le choix des méthodes d'apprentissage demande du travail et des connaissances sur le sujet... mais ce n'est probablement pas le point critique.
A terme, pour enrichir la base d'apprentissage, et pour être dans l'air du temps... imaginer un site "contributif" dans lequel les visiteurs pourraient à la fois jouer à reconnaître des sons, mais aussi enrichir la base de son par des sons nouveaux... serait le moyen le plus économique et le plus efficace d'étendre les capacités fonctionnelles du projet.
Deuxième réaction :
Comme pour tout travail de recherche scientifique, il sera ici crucial de dresser un état de l'art en recherchant les connaissances déjà acquises (ou supposées) dans le domaine.
Notamment, chercher à comprendre comment fonctionne Shazam en particulier, ou la reconnaissance vocale en général...
Et bien sûr transposer ça à ton problème à toi (qui est différent de celui de Shazam).
Exemple de lien : ![]()
Citation :
.../...
Pour comprendre, j'ai un peu fouillé et trouvé que la technologie appartient à Landmark Digital qui a notamment acquis la propriété intellectuelle de dénommés Avery Wang et David Culbert. Leur brevet de 2003 [1] est un modèle du genre : il décrit le système en termes suffisamment généraux pour comprendre le principe, mais en évitant soigneusement de donner des informations précises sur comment ça marche vraiment. Mais voici tout de même ce que j'en ai compris.
Shazam compare des « empreintes » calculées à des instants remarquables du morceau, par exemple lorsque des notes apparaissent nettement dans le diagramme temps/fréquence du morceau. Pour des raisons expliquées plus bas il faut comparer environ une centaine d'empreintes, et comme Shazam demande d'enregistrer une dizaine de secondes de musique, j'en déduis qu'ils prennent environ 10 empreintes par seconde, donc que chaque morceau est stocké chez eux sous la forme de 1800 empreintes environ.
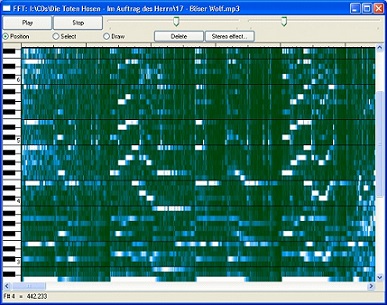
FFT est un joli petit programme qui affiche le diagramme temps/fréquence dun mp3
« FFT » est un joli petit programme qui affiche le diagramme temps/fréquence d'un mp3
Le brevet est extrêmement vague sur le problème clé du calcul des empreintes. Il mentionne une liste de caractéristiques du son qui pourraient être utilisées, et indique qu'un choix judicieux permet de s'affranchir de diverses perturbations du son, en particulier de décalages fréquentiels, mais surtout que l'empreinte peut être ramenée à un nombre de 32 bits seulement. Avec ce qui précède, il en résulte que les empreintes d'un morceau complet ne nécessitent que 7K de mémoire, et que toute la base de données de Shazam tient sur 54 Gigabytes seulement, ce qui veut dire qu'elle peut tenir dans la mémoire RAM d'une vingtaine de PC actuels.
.../...
.../...
Pour comprendre, j'ai un peu fouillé et trouvé que la technologie appartient à Landmark Digital qui a notamment acquis la propriété intellectuelle de dénommés Avery Wang et David Culbert. Leur brevet de 2003 [1] est un modèle du genre : il décrit le système en termes suffisamment généraux pour comprendre le principe, mais en évitant soigneusement de donner des informations précises sur comment ça marche vraiment. Mais voici tout de même ce que j'en ai compris.
Shazam compare des « empreintes » calculées à des instants remarquables du morceau, par exemple lorsque des notes apparaissent nettement dans le diagramme temps/fréquence du morceau. Pour des raisons expliquées plus bas il faut comparer environ une centaine d'empreintes, et comme Shazam demande d'enregistrer une dizaine de secondes de musique, j'en déduis qu'ils prennent environ 10 empreintes par seconde, donc que chaque morceau est stocké chez eux sous la forme de 1800 empreintes environ.
FFT est un joli petit programme qui affiche le diagramme temps/fréquence dun mp3
« FFT » est un joli petit programme qui affiche le diagramme temps/fréquence d'un mp3
Le brevet est extrêmement vague sur le problème clé du calcul des empreintes. Il mentionne une liste de caractéristiques du son qui pourraient être utilisées, et indique qu'un choix judicieux permet de s'affranchir de diverses perturbations du son, en particulier de décalages fréquentiels, mais surtout que l'empreinte peut être ramenée à un nombre de 32 bits seulement. Avec ce qui précède, il en résulte que les empreintes d'un morceau complet ne nécessitent que 7K de mémoire, et que toute la base de données de Shazam tient sur 54 Gigabytes seulement, ce qui veut dire qu'elle peut tenir dans la mémoire RAM d'une vingtaine de PC actuels.
.../...
Nous vous remercions pour vos réponses rapides et instructives  , vous nous avez confirmé l'ampleur de la tache à réaliser !
, vous nous avez confirmé l'ampleur de la tache à réaliser !
On va donc se pencher plus sérieusement sur la FFT que nous avions envisagé mais qui apparemment est la méthode la plus efficace, du moins pour les sons répétitifs, car le problème qui arrive maintenant, c'est que nous n'étudieront pas (uniquement) des chansons qui ne changent jamais, un oiseau ne fait pas forcément tout le temps exactement le même son, mais il faudrait pourtant que nous le reconnaissions peu importe le son qu'il fait. Pour le moment, on a déjà pris un rendez-vous avec un ingénieur acoustique qui pourra surement nous aider à comprendre comment réaliser notre expérience finale : reconnaître lequel de nous quatre parle, pour la partie "moteur de recherche" il faudra juste faire un programme qui lancera le résultat de l'expérience dans une recherche internet.
Cependant nous n'arrivons pas encore à saisir de quelle manière réaliser des identifications audio par empreinte, peut être que l'ingénieur acoustique nous aidera à ce sujet.
Merci encore pour vos réponses
Et bonne année a vous! 
Citation :
... pour la partie "moteur de recherche" il faudra juste faire un programme qui lancera le résultat de l'expérience dans une recherche internet
Le moteur de recherche est un sujet à part.
... pour la partie "moteur de recherche" il faudra juste faire un programme qui lancera le résultat de l'expérience dans une recherche internet
Il faut d'abord trouver un dispositif capable de reconnaître la nature du son.
Une fois trouvé le dispositif, il faudra (ultérieurement) l'implémenter dans un moteur de recherche, qui soulève des questions techniques complètement différentes. Je ne crois pas que l'on puisse traiter deux sujets aussi distincts dans un TIPE. Et vous avez dix minutes pour présenter votre travail... Il vous suffit de dire en introduction que le moteur est le but (pour des raisons d'enjeux évidents : les ressources sont sous employées par manque d'information sur leur contenu sonore). Puis de dire en conclusion que le procédé de reconnaissance que vous avez étudié fait progresser la connaissance pour se rapprocher du but final.
Eventuellement, vous pouvez expliquer brièvement et de façon conceptuelle, comment le moteur procèderait : scan des pages, repérage de sons, analyse, reconnaissance, utilisation dans les critères de recherche (éventuellement plus globaux : propriété du son + mots clés de recherche textuelle classique). Pour des raisons d'optimisation, l'analyse pourrait être réalisée en grande partie par avance (et une fois pour toute) pour chaque ressource Internet, de sorte que les éléments identifiant le son soient disponibles au moment de la recherche... Mais tout ça ce sont des "fioritures" par rapport au vrai sujet scientifique que vous avez posé.
Citation :
notre expérience finale : reconnaître lequel de nous quatre parle
Hyper ambitieux ! Et très centré sur la reconnaissance vocale...
notre expérience finale : reconnaître lequel de nous quatre parle
Je suggère d'élargir à la reconnaissance d'une caractéristique plus facile à identifier. Par exemple peut on reconnaître un son de trompette parmi plein de sons quelconques (quoique ça fait le même sujet si l'un de vous à une voix de trompette
 )...
)...
Pour faire ça, il faudra plus s'attacher au spectre, qu'à sa dynamique (variation des fréquences dans le temps, qui constitue une signature forte pour des morceaux musicaux notamment). Encore qu'à la réflexion, il est possible que des fluctuations légères de fréquences puissent constituer une signature d'empreinte sonore : le son est un domaine tellement vaste...
Vous devrez sûrement voir comment on peut modéliser le timbre notamment. C'est compliqué. C'est en rapport avec la "forme" du spectre. Il y a beaucoup d'exploration ou de lectures d'articles à faire... Simplifiez-vous la vie en prenant quelque chose de simple à reconnaître pour commencer. Ou alors trouvez un expert méchamment bon
!
Si un expert de la reconnaissance sonore est capable de vous dire aujourd'hui par exemple, il y a trois manières fondamentales de modéliser un son et les pistes les plus prometteuses pour la reconnaissances consistent à étudier telle ou telle représentation qui préserve le maximum d'informations sur le contenu sonore... alors ensuite vous pouvez vous ramener à un problème d'apprentissage (ou modélisation mathématique si tu préfères) appliqué à une base de sons correctement instruite.
Ne pas sous-estimer le sujet qui est énorme !
Et avancer à pas mesurés...
En effet, nous nous sommes mal exprimé. Le moteur de recherche en question représentera l'accomplissement théorique du projet. Cela prendrait un temps fou pour le réaliser alors que le gros de notre travail cible l'analyse des sons en eux mêmes. Il nous faudra bien sûr le mentionner dans notre compte rendu.
En réalité, nous voulions chacun répéter une même phrase puis caractériser le spectre de chacun pour qu'à la sortie si l'un de nous répétions cette même phrase en gardant la même voix approximativement, le dispositif puisse identifier l'un de nous. Cela ne reviendrait-il pas à l'étude du son d'une trompette (oui car malheureusement aucun de nous n'a la possibilité d'imiter la trompette  ) dans un milieu sonore ? Si vous pensez que la trompette est plus facile à identifier, il serait certes plus judicieux de commencer par les choses les plus simples !
) dans un milieu sonore ? Si vous pensez que la trompette est plus facile à identifier, il serait certes plus judicieux de commencer par les choses les plus simples !
Citation :
Pour faire ça, il faudra plus s'attacher au spectre, qu'à sa dynamique
Pour faire ça, il faudra plus s'attacher au spectre, qu'à sa dynamique
Que voulez vous dire par là ? Est ce que vous appelez la "forme" du spectre ?
Citation :
alors ensuite vous pouvez vous ramener à un problème d'apprentissage (ou modélisation mathématique si tu préfères)
alors ensuite vous pouvez vous ramener à un problème d'apprentissage (ou modélisation mathématique si tu préfères)
Nous ne saisissons pas entièrement ces termes..

Citation :
En réalité, nous voulions chacun répéter une même phrase puis caractériser le spectre de chacun pour qu'à la sortie si l'un de nous répétions cette même phrase en gardant la même voix approximativement, le dispositif puisse identifier l'un de nous. Cela ne reviendrait-il pas à l'étude du son d'une trompette (oui car malheureusement aucun de nous n'a la possibilité d'imiter la trompette ) dans un milieu sonore ?
La difficulté c'est de trouver dans le son une "signature" qui permettent de distinguer une identité sonore (au sens large).
En réalité, nous voulions chacun répéter une même phrase puis caractériser le spectre de chacun pour qu'à la sortie si l'un de nous répétions cette même phrase en gardant la même voix approximativement, le dispositif puisse identifier l'un de nous. Cela ne reviendrait-il pas à l'étude du son d'une trompette (oui car malheureusement aucun de nous n'a la possibilité d'imiter la trompette ) dans un milieu sonore ?
Il est certainement possible de reconnaître une voix parmi d'autres puisque le principe de l'identification vocale existe en criminalistique. Mais c'est très complexe à réaliser et je doute que vous ayez les moyens d'y parvenir dans le cadre d'un simple TIPE.
Cela dit, rien ne vous interdit de vous enregistrer (plusieurs fois chacun) et d'observer si vos spectres respectifs ont des caractéristiques différenciables (et reproductibles). Je crains juste que ce ne soit assez complexe. Et c'est de toutes façons imprévisible a priori.
Citation :
Si vous pensez que la trompette est plus facile à identifier, il serait certes plus judicieux de commencer par les choses les plus simples !
En fait je ne sais pas si une trompette est plus spécialement reconnaissable. Disons simplement que si vous élargissez votre champ d'étude, vous avez plus de chances de repérer une caractéristique différenciatrices. Et effectivement, dans votre recherche, il est de toutes façons plus judicieux de commencer par des choses plus simples, quitte à élever la difficulté ensuite si vous en avez le temps et la possibilité.
Si vous pensez que la trompette est plus facile à identifier, il serait certes plus judicieux de commencer par les choses les plus simples !
Citation :
"Pour faire ça, il faudra plus s'attacher au spectre, qu'à sa dynamique"
Que voulez vous dire par là ? Est ce que vous appelez la "forme" du spectre ?
Un son bouge. Le spectre est un concept instantané : c'est la distribution des fréquences à l'instant t. Une séquence sonore qui n'est pas constante va donc voir cette distribution évoluer dans le temps.
"Pour faire ça, il faudra plus s'attacher au spectre, qu'à sa dynamique"
Que voulez vous dire par là ? Est ce que vous appelez la "forme" du spectre ?
Si tu veux reconnaître une chanson ou une musique, comme dans Shazam, tu vas surtout t'intéresser à l'évolution dans le temps des fréquences dominantes, qui correspondent aux notes de musique jouées. Si tu repères MI MI FA SOL SOL FA MI RE DO DO RE MI MI RE RE ... tu reconnaitras directement la 9ème de Beethoven. Et même si l'air est joué transposé (en partant d'une autre note) ce n'est pas un problème : les rapports de fréquences seront identifiables également. Donc dans ce type de reconnaissance, tu t'intéresses clairement à la dynamique du spectre, c'est à dire à ses variations dans le temps.
Mais si tu t'intéresses plutôt au "timbre" d'un son, il semble raisonnable de considérer un son "stable", c'est à dire avec un spectre qui reste à peu près constant dans le temps. Et dans ce cas c'est la "forme" de la distribution des fréquences qui servira de base à ton travail d'identification.
Par exemple, un "bruit" au sens théorique, correspond à une distribution uniforme des fréquences. C'est une "soupe sonore" où aucune fréquence particulière n'est discernable.
Tandis qu'un son pur (sinusoïde parfaite), par exemple un LA de diapason, correspond à un pic sur la fréquence 440 Hz.
Et une note d'instrument aura un spectre avec des fréquences dominantes qui formeront des pics qui correspondront aux fréquences les plus audibles. Ces fréquences dominantes (celles avec une puissance maximale) seront généralement dans des rapports harmoniques (multiples et sous multiples de fréquences correspondant à la note jouée et à ses harmoniques).
Citation :
"alors ensuite vous pouvez vous ramener à un problème d'apprentissage (ou modélisation mathématique si tu préfères)"
--> Nous ne saisissons pas entièrement ces termes.
Ce n'est ni grave ni important.
"alors ensuite vous pouvez vous ramener à un problème d'apprentissage (ou modélisation mathématique si tu préfères)"
--> Nous ne saisissons pas entièrement ces termes.
C'est juste une piste de réflexion parmi d'autres possibles autour de ton sujet.
L'apprentissage consiste à constituer une base de sons, dont on connait la caractéristique à identifier (en instruisant la base).
Ensuite on cherche un algorithme ou formule mathématique qui exploite les données du spectre pour calculer un score. Si ce score est faible : l'identification n'est pas faite. Si le score est fort, le son est identifié. Tout cela est guidé par une démarche et des outils statistiques (régression, analyse discriminante, etc...).
Dans votre cas, vous pouvez évoquer cette démarche "générale", mais pour votre expérience vous vous limiterez à un algorithme simple qui vous convient pour reconnaître la particularité que vous voulez identifier.
Exemple, si pour une note jouée par une trompette, les trois fréquences dominantes sont dans un rapport donné, et que les niveaux sonores correspondants à ces fréquences sont aussi dans un certain rapport qui est typique, alors le score sera simple à construire : il mesurera si les fréquences dominantes et les niveaux associés respectent ces rapports.
D'accord vous avez raison, il est préférable de ne pas commencer par une analyse vocale. Il serait peut être intéressant aussi d'étudier le son d'une trompette par exemple en fonction du milieu sonore, c'est-à-dire voir à à partir de quelle intensité du milieu sonore l'identification de notre son devient impossible.
Peut-être alors qu'une analyse du son en 3 dimensions (fréquence,temps et amplitude) nous permettrait l'identification d'un son plus facilement. Quoique non, vu que chaque reproduction d'un son est unique, lui ajouter une composante d'amplitude ne serait que superficiel.
Nous partons donc pour identifier réellement la signature d'un son, les motifs qui nous permettrons de le distinguer. Nous pourrions intégrer des filtres passe haut ou bas pour limiter les fréquences étudiées.